The 180ms Constraint Decides More Than You Think
You are a mid-level AI Engineer at a leading tech company. The recommendations team wants to replace heuristic feed ranking with a learning-based system for 40 million daily active users. Peak traffic: 120,000 requests per second. Required end-to-end latency: 180ms p95.
Most candidates hear "ML system design" and start designing a model. The interviewer is waiting for them to notice something else first: at 120k req/sec and 180ms p95, the full ML inference pipeline cannot run synchronously on every request. That single observation, surfaced in the first three minutes, shapes everything that follows. Candidates who miss it spend the rest of the interview designing a system that looks architecturally complete but cannot actually serve at scale. The AI Engineer ML system architecture mock interview on InterviewStack.io runs this exact scenario with the same four-phase blueprint.
Key Findings
- 60 of 100 rubric points go to Interviewer Objectives Alignment (30 pts) and Level-Specific Expectations (30 pts), not technical accuracy alone.
- Phase 1 (0-8 min) carries 4 checklist items, all about scoping: stating assumptions, proposing a layered architecture, recognizing multi-stage retrieval plus ranking, and naming a graceful fallback.
- Phase 2 (8-18 min) has 5 checklist items covering data pipelines, feature design, and the training lifecycle, including time-correct label joining and data validation before model promotion.
- Phase 3 (18-27 min) has 5 checklist items on serving latency, monitoring dimensions, rollout safety, and identifying at least 2 failure modes with concrete mitigations.
- Phase 4 (27-30 min) has 3 checklist items: summarize the architecture in 1-2 minutes, name the main bottlenecks or failure modes, and explain at least one trade-off to revisit.
- The scenario specifies 120,000 requests per second peak and 180ms p95, making synchronous full-pipeline inference at serve time impossible without precomputed candidates and cached features.
- New videos must become eligible for recommendation within 10 minutes, creating a freshness constraint that batch-only pipelines cannot satisfy on their own.
How Is an AI Engineer ML System Architecture Interview Scored?
The rubric has four dimensions, but the weight is not even. Technical Proficiency (correct tool choices, sound design decisions) is worth 20 points. Communication and Problem Solving (structure, ambiguity handling, clarifying questions) is worth another 20. The remaining 60 go to two framing dimensions: whether your design actually addresses the specific problem the interviewer set (Interviewer Objectives Alignment, 30 pts) and whether you show the judgment expected at the mid level (Level-Specific Expectations, 30 pts).
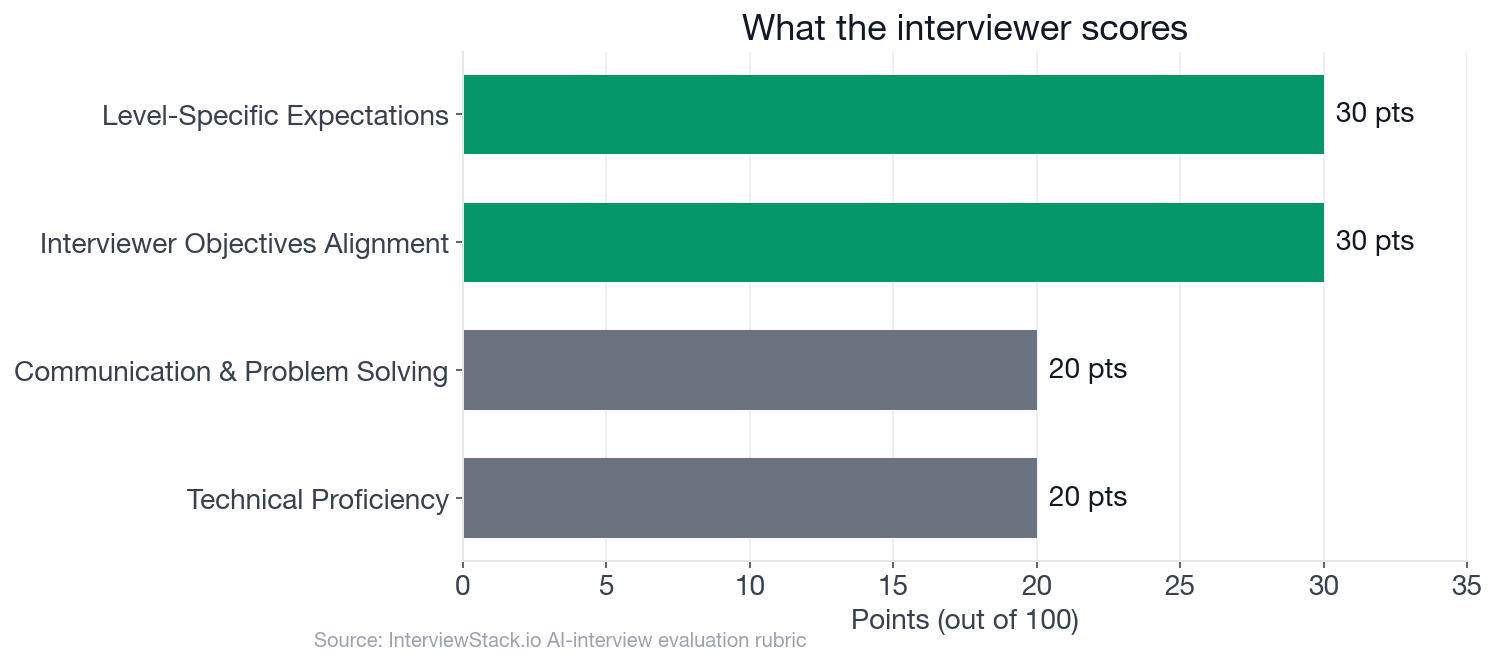
Those two framing dimensions reward candidates who scope the problem, state their assumptions, and anchor every design decision to a stated constraint. A candidate who designs a sophisticated neural ranking model but never mentions the graceful fallback path is missing an explicit Phase 1 checklist item, which means conceding points in the two 30-point dimensions before the first follow-up arrives.
The Interview Question
The interview question
You are supporting a consumer video platform. The recommendations team wants to improve the ranking of videos on the home feed for signed-in users. Today, the feed uses mostly heuristic rules and simple popularity signals. Product wants a learning-based ranking system that can use user behavior, video metadata, and recent engagement events.
Constraints: - ~40 million daily active users - ~8 million videos in the catalog - Peak home-feed request rate: 120k requests/second globally - The ranking service must return results within 180 ms p95 end-to-end - New videos should become eligible for recommendation within 10 minutes - User interaction events arrive continuously from mobile and web clients - The business is sensitive to outages; if ML components fail, the feed must still degrade gracefully - A small platform team will own the system, so operational complexity matters
Design the machine learning system architecture for this home-feed ranking system, and walk through how data and models would move from ingestion through training to production serving and maintenance.
The interviewer is assessing whether you can scope the recommendation problem, choose a sensible multi-stage architecture (candidate retrieval followed by ranking, not a single monolithic scorer), treat the latency and freshness constraints as architectural forcing functions rather than footnotes, and name the graceful degradation path before anyone asks for it.
The Walkthrough: Four Turns Where Candidates Lose Points
Turn 1: Batch vs. Real-Time Split
Interviewer: "How would you split responsibilities between batch and real-time pipelines in this design, and what would you store in each path?"
Turn 2: Fresh Signals Within Minutes
Interviewer: "If product asks that very recent user actions affect recommendations within a few minutes, what changes would you make to the feature and serving architecture?"
Turn 3: The CTR Offline-to-Production Gap
Interviewer: "Suppose click-through rate improves in offline evaluation but drops after deployment for some regions. How would you investigate and what signals would you monitor?"
Turn 4: Rollout, Fallback, and Rollback
Interviewer: "How would you handle model rollout, fallback, and rollback so that a bad model or feature pipeline does not take down the home feed?"
Spotting Mistakes on the Page Is Not the Same as Avoiding Them Live
You can read the four turns above in five minutes. Avoiding the same mistakes during a live 30-minute session, with follow-up questions you have not seen, mid-sentence redirects from the interviewer, and the clock ticking through Phase 2, is the actual skill gap. The batch-vs-real-time turn, the freshness question, the regional CTR drop: each one interrupts a candidate who was mid-thought on a different thread.
Browse open AI Engineer roles on the job board to see the system-level scope companies are actually testing for right now. Drill the ML system architecture question bank to build vocabulary before the live session. Then start the AI Engineer ML System Architecture mock interview to practice under the same 30-minute blueprint with real-time feedback on all four rubric dimensions.
The Complete Blueprint
This is the blueprint a strong candidate follows, and the exact framework the AI mock interview tracks you against in real time.
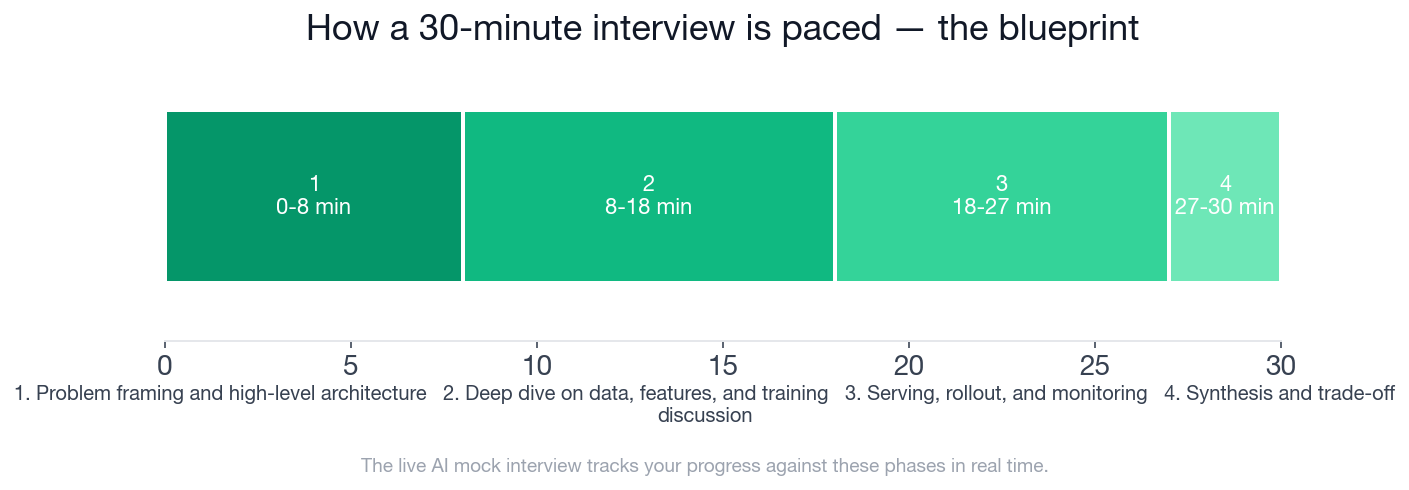
The four-phase timeline allocates the first eight minutes to framing and architecture, the next ten to data and training, the following nine to serving and monitoring, and a closing three to synthesis and trade-off discussion.
- ✓States assumptions about scale, latency, feature freshness, and success metrics.
- ✓Identifies key stages such as event logging, storage, feature pipelines, training, validation, serving, and monitoring.
- ✓Explains data flow in a logical sequence rather than listing disconnected tools.
- ✓Distinguishes offline training path from online inference path.
- ✓Chooses plausible ingestion and storage patterns such as streaming events plus durable offline storage.
- ✓Explains how features are computed and shared across offline and online use cases.
- ✓Calls out training-serving skew or feature freshness risks and proposes mitigation such as shared feature definitions or point-in-time joins.
- ✓Includes model evaluation and validation gates before registration or deployment.
- ✓Mentions reproducibility mechanisms such as versioned data, code, configs, or experiment tracking.
- ✓Describes a serving path that is compatible with low-latency ranking, including feature retrieval and model inference placement.
- ✓Provides a controlled rollout plan such as shadow, canary, region-based, or percentage rollout with rollback strategy.
- ✓Defines monitoring beyond service uptime, including data quality, feature drift, model performance, and business metrics.
- ✓Explains fallback behavior for missing features, upstream delays, or degraded dependencies.
- ✓Describes a feedback loop for collecting labels/outcomes and triggering retraining or review.
- ✓Summarizes the architecture clearly in 1-2 minutes.
- ✓Names the main bottlenecks or failure modes in their design.
- ✓Explains at least one trade-off they would revisit as scale or product requirements evolve.
FAQ
Q. What are the four phases of a mid-level AI Engineer machine learning system architecture interview?
The 30-minute blueprint covers four phases: problem framing and high-level architecture (0-8 min, 4 checklist items), deep dive on data, features, and training (8-18 min, 5 checklist items), serving, rollout, and monitoring (18-27 min, 5 checklist items), and synthesis and trade-off discussion (27-30 min, 3 checklist items). Framing and level-specific expectations together account for 60 of 100 rubric points.
Q. Why does the 180ms p95 latency constraint matter in an ML system design interview?
At 120,000 requests per second with a 180ms p95 ceiling, the ranking service cannot run full model inference synchronously on every request. The constraint forces a precomputed architecture: candidate sets and long-term features must be materialized offline or cached, leaving serving only to perform lightweight feature lookup and scoring.
Q. What is training-serving consistency and why do interviewers test it?
Training-serving consistency means the features the model trains on and the features it sees at inference time are computed identically. When they differ, the model's offline metrics stop predicting production behavior. Interviewers test it because it is one of the most common and costly silent failure modes in production ML systems.
Q. What is the most common mistake in an ML system architecture interview at the mid-level?
Spending the first 8 minutes deep in model architecture details (loss functions, hyperparameters, layer design) before establishing system constraints, the multi-stage retrieval plus ranking flow, and the graceful fallback path. The framing phase (0-8 min) carries 4 explicit checklist items that set up the entire rest of the interview.
Q. How should a mid-level AI Engineer candidate handle the CTR offline-to-production gap question?
Start with monitoring segmentation, not retraining. A CTR drop in specific regions after offline improvement can signal training-serving skew, feature null rate issues, or label quality differences. The correct order is: check feature distributions and null rates in serving logs, compare prediction score distributions by region, then decide whether the root cause is a data or model issue before committing to a fix.
Q. What fallback strategy should candidates propose for an ML recommendation system?
The ranking API should maintain a synchronous heuristic fallback path (recent and popular content) that activates automatically when the ML service exceeds latency bounds or error thresholds. Rollout adds shadowing before canary, with automatic ramp-down on CTR drop or serving latency spike. Rollback is pointing serving at the previous model registry version, not a redeploy.
What the Four Phases Are Actually Testing
Each phase tests a different kind of judgment. Phase 1 tests whether you understand the problem well enough to constrain your design before committing to it. Phase 2 tests whether you know what corrupts data and model quality at scale before a single user sees a prediction. Phase 3 tests whether you can run a system you cannot afford to take offline. Phase 4 tests whether you can step back and name the highest-risk parts of your own design clearly and concisely. The 180ms constraint is just the most visible version of the Phase 3 question: it forces you to decide, on the spot, what gets precomputed and what stays live. Get that boundary wrong in Phase 1 and every downstream answer builds on a broken foundation. Explore open AI Engineer positions on the job board to see how companies are scoping this role right now.
Topics
Ready to practice?
Put what you've learned into practice with AI mock interviews and structured preparation guides.