The Model-Building Skills Don't Move Data Scientist Salary
Open any Data Science bootcamp curriculum and you will find PyTorch, TensorFlow, and scikit-learn front and center. Open a job board and you will find them in roughly one in eight postings. But check what those postings actually pay: PyTorch sits at $125,000 median in the US, TensorFlow at $122,000, Machine Learning as a broad category at $125,000. Against a role baseline of $125,000, the frameworks most associated with the job description of "Data Scientist" deliver nearly zero salary premium.
A/B Testing, which rarely headlines DS curricula compared to those frameworks, commands $152,000 median. That is a $27,000 premium over the baseline. dbt (a SQL transformation framework that runs inside the data warehouse, letting teams define data models as versioned code) sits at $161,500, a $36,500 premium. MLOps adds $16,200. MLflow adds $29,000. The pattern is not about which tools are harder to learn. It is about which skills the market cannot easily replace: the layer between notebook and production, where experiments turn into business impact and models turn into monitored deployments.
We looked at 7,693 active Data Scientist postings on the InterviewStack.io job board as of June 2026, with skills extracted and synonyms normalized, to map where those rewards actually sit.
Dataset note: This sample reflects the job board's "Data Scientist" role classification. A review of job titles in the dataset shows the large majority are core Data Scientist roles; a smaller portion includes adjacent positions such as quantitative analysts, data stewards, and research scientists. Individual skill percentages reflect this broad composition, though the rank-ordering of skills and the salary picture are consistent with the genuine Data Scientist market.
Key Findings
- 7,693 active Data Scientist postings analyzed on the InterviewStack.io job board as of June 2026.
- Python is the only table-stakes skill, appearing in 63.2% of postings (4,865 of 7,693). SQL (48.3%), Statistics (48.1%), and Machine Learning (47.7%) each appear in roughly half of postings.
- Median US base salary: $125,000 across 1,504 postings with US salary disclosed.
- A/B Testing pays $152,000 median (n=467), a $27K premium. dbt pays $161,500 (n=56, +$36.5K). MLOps pays $141,200 (n=138, +$16K).
- PyTorch ($125,000, n=187) and TensorFlow ($122,000, n=181) sit at or below the role median: the ML frameworks most associated with the title deliver near-zero salary premium.
- New-wave AI (LLMs 17.8%, Generative AI 13.7%) appears in roughly 21% of postings, measuring explicitly build-with-AI roles. AI tool usage is already the ambient expectation across the whole field.
- Entry-level is 8.8% of postings (675 of 7,693), comparable to Data Analyst; mid-level is 55.7% (4,285); senior plus staff combined are 35.5% (2,733).
- Onsite leads at 48.4% of postings, hybrid 29.7%, remote 17.7%: a tighter remote picture than Data Engineer roles.
Which Data Scientist Skills Pay Above the $125K Baseline?
The numbers below are US-only base salary, drawn from postings where wage-transparency laws produce consistent disclosure. Equity, bonuses, RSUs, and sign-on are not captured in posting data, so total compensation at top employers, especially in tech and finance, runs meaningfully higher than what we report here.
The overall US median is $125,000 (n=1,504 postings with salary disclosed).
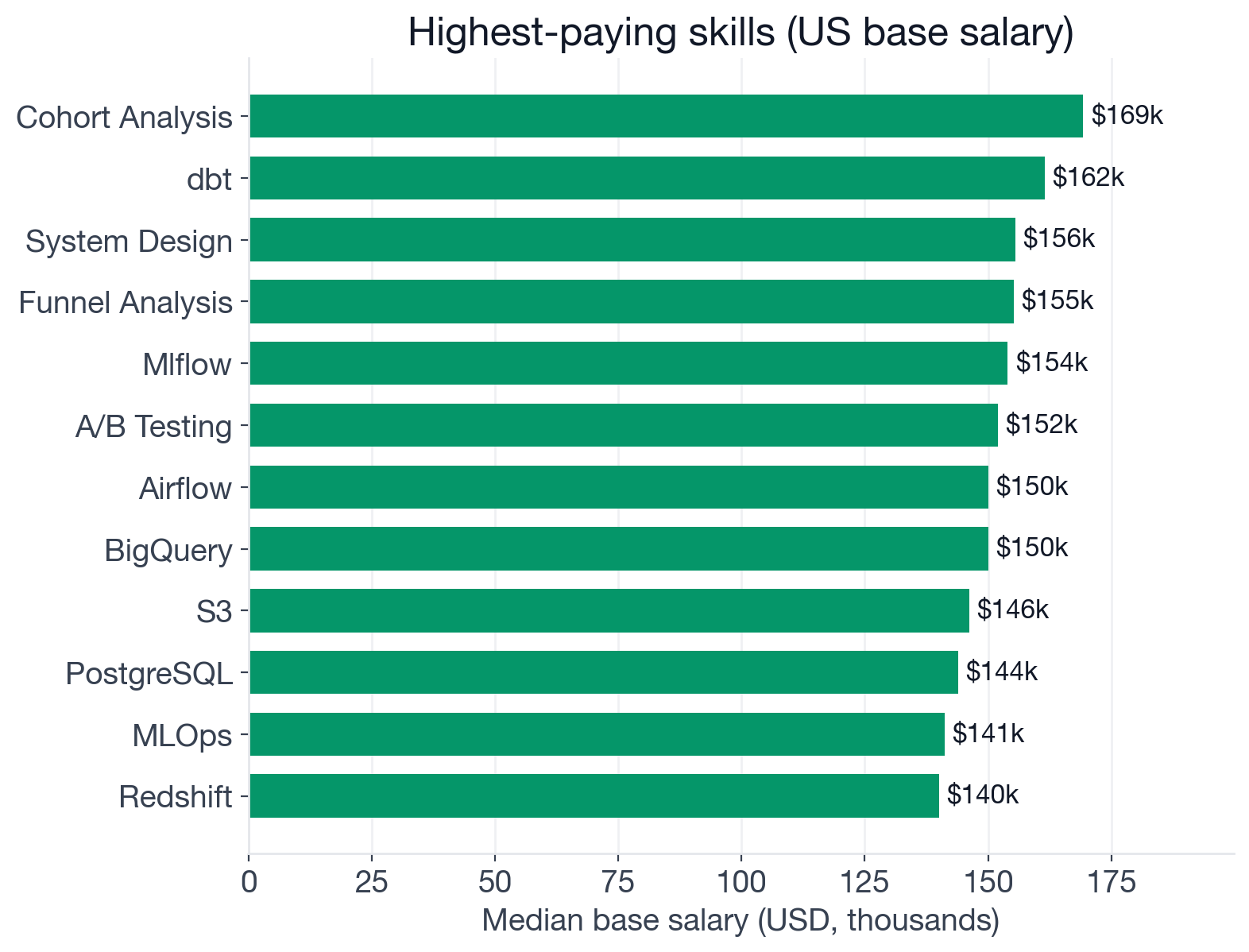
Median US base salary for Data Scientist postings that mention each skill. US postings only, base salary only.
| Skill | US Median | n | vs. $125K baseline |
|---|---|---|---|
| dbt | $161,500 | 56 | +$36,500 |
| MLflow | $154,000 | 36 | +$29,000 |
| A/B Testing | $152,000 | 467 | +$27,000 |
| MLOps | $141,200 | 138 | +$16,200 |
| Deep Learning | $135,000 | 155 | +$10,000 |
| Monitoring | $135,000 | 351 | +$10,000 |
| Snowflake | $135,000 | 138 | +$10,000 |
| Forecasting | $133,500 | 196 | +$8,500 |
| Generative AI | $130,000 | 229 | +$5,000 |
| Python | $126,000 | 1,083 | +$1,000 |
| PyTorch | $125,000 | 187 | $0 |
| Machine Learning | $125,000 | 838 | $0 |
| TensorFlow | $122,000 | 181 | -$3,000 |
| NLP | $115,800 | 156 | -$9,200 |
| LangChain | $107,500 | 52 | -$17,500 |
The top four share a common theme: they all move science toward production and toward a measurable outcome. dbt signals a Data Scientist who works fluidly across the analytics engineering layer, not just the modeling layer. MLflow (an open-source experiment-tracking and model-registry tool) and MLOps signal someone who can take a model from notebook to a monitored, versioned deployment. A/B Testing signals someone who can close the loop between a model's predictions and an actual business result.
The ML frameworks, PyTorch, TensorFlow, scikit-learn, and Machine Learning broadly, have become so expected that they have priced into the baseline. Hiring managers assume them; they do not pay extra for them.
Two entries well below baseline deserve notice. NLP at $115,800 and LangChain at $107,500 both lag significantly. The "build me a chatbot or RAG pipeline" category draws more junior candidates who know Python and LLM APIs but have not built production systems, compressing the median downward. A seasoned NLP specialist is not being paid less; the posting category just contains more variability than the label implies.
What Skill Families Make Up the Data Scientist Stack?
Group every individual skill into its broader family and the role's shape becomes legible: it is not a single specialty, but four overlapping layers that hiring managers expect on the same resume.
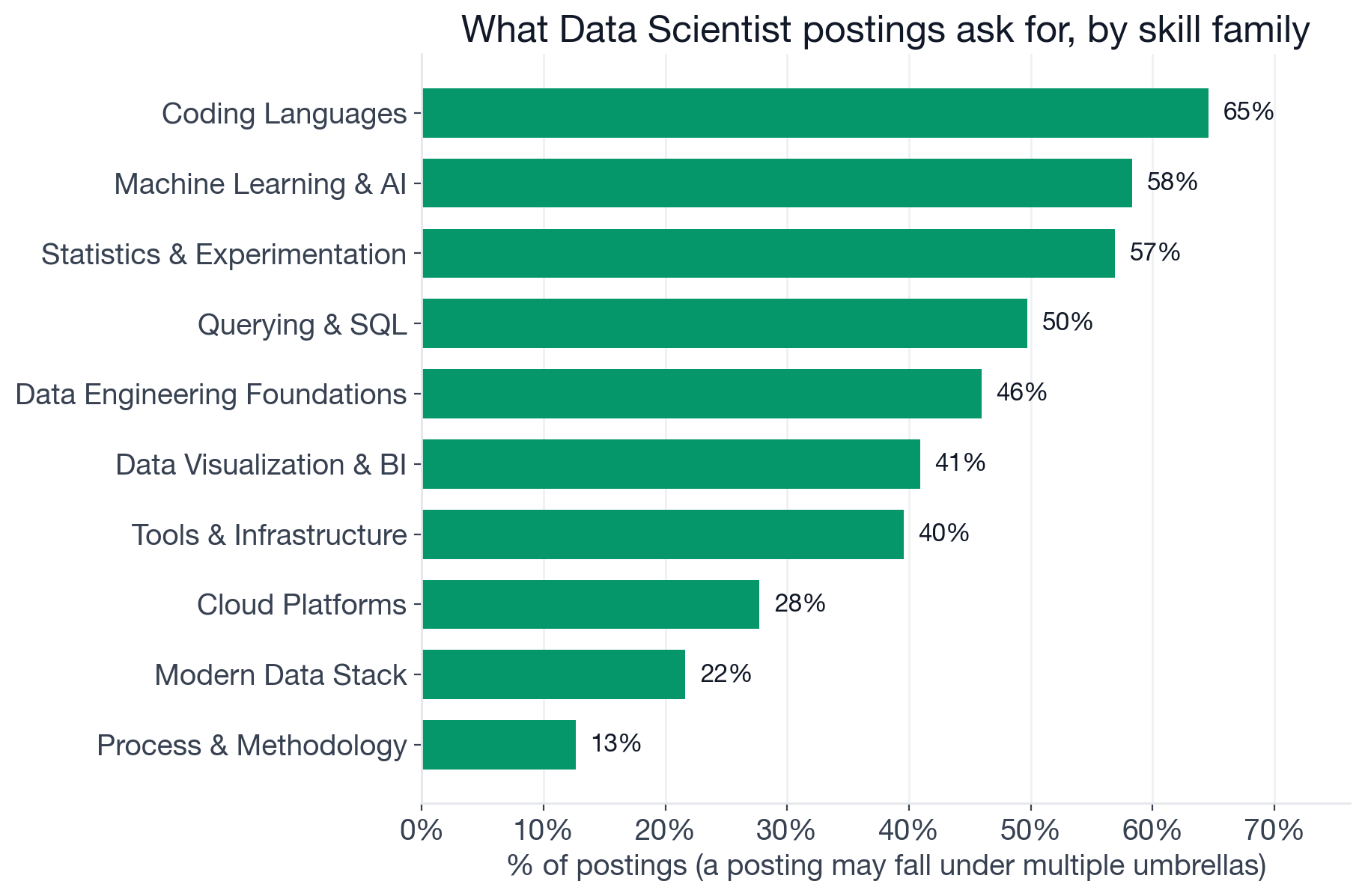
Share of Data Scientist postings asking for at least one skill in each family. A posting mentioning both PyTorch and TensorFlow counts once under "Machine Learning and AI."
The top four families define the role's core identity:
- Coding Languages (64.6%): Almost entirely Python, with Java and TypeScript appearing in a long tail that likely reflects adjacent engineering roles at the boundary of the dataset.
- Machine Learning and AI (58.3%): Classical ML anchors this family at 47.7%, with LLMs, deep learning, NLP, MLOps, and the growing GenAI layer underneath.
- Statistics and Experimentation (56.9%): Statistics (48.1%), A/B Testing (22.9%), forecasting, time series, regression. Nearly as demanded as ML itself, and paying more when paired with experimentation design.
- Querying and SQL (49.7%): Half the market still asks for SQL explicitly. For roles at companies with mature data platforms, SQL is the interface to the warehouse, and a Data Scientist who cannot write production-quality queries hands off too much work to engineers.
Data Engineering Foundations (46.0%) and Data Visualization and BI (40.9%) add the expected breadth: sourcing the data and communicating the result are both considered part of the job.
Cloud Platforms appear in only 27.7% of postings, compared to 63% for Data Engineer roles. Data Scientists are generally not provisioning infrastructure. The cloud expectation is more often "use the services your team provides" than "design and deploy them yourself."
The Machine Learning and AI family contains something worth pausing on. Classical ML sits at 47.7%, but the new-wave layer is much narrower: LLMs at 17.8%, Generative AI at 13.7%. Together, roughly 21% of postings explicitly require building or architecting AI systems. The other 79% do not mention it because companies treat AI tool fluency as an ambient expectation, not a specialized qualification.
Developer survey data backs this up. The Stack Overflow Developer Survey 2025 found 84% of developers were using or planning to use AI tools, and 51% used them daily. A JetBrains survey of 10,000+ developers in January 2026 found 90% regularly use at least one AI tool at work. For data and engineering roles specifically, the OpenAI State of Enterprise AI 2025 found these teams save 60 to 80 minutes per active workday using AI tools. Writing Python in a Jupyter notebook without Copilot or ChatGPT nearby is already the minority experience. Whether the posting lists it or not is irrelevant to whether it is expected.
Three Tiers of Data Scientist Skills in 2026
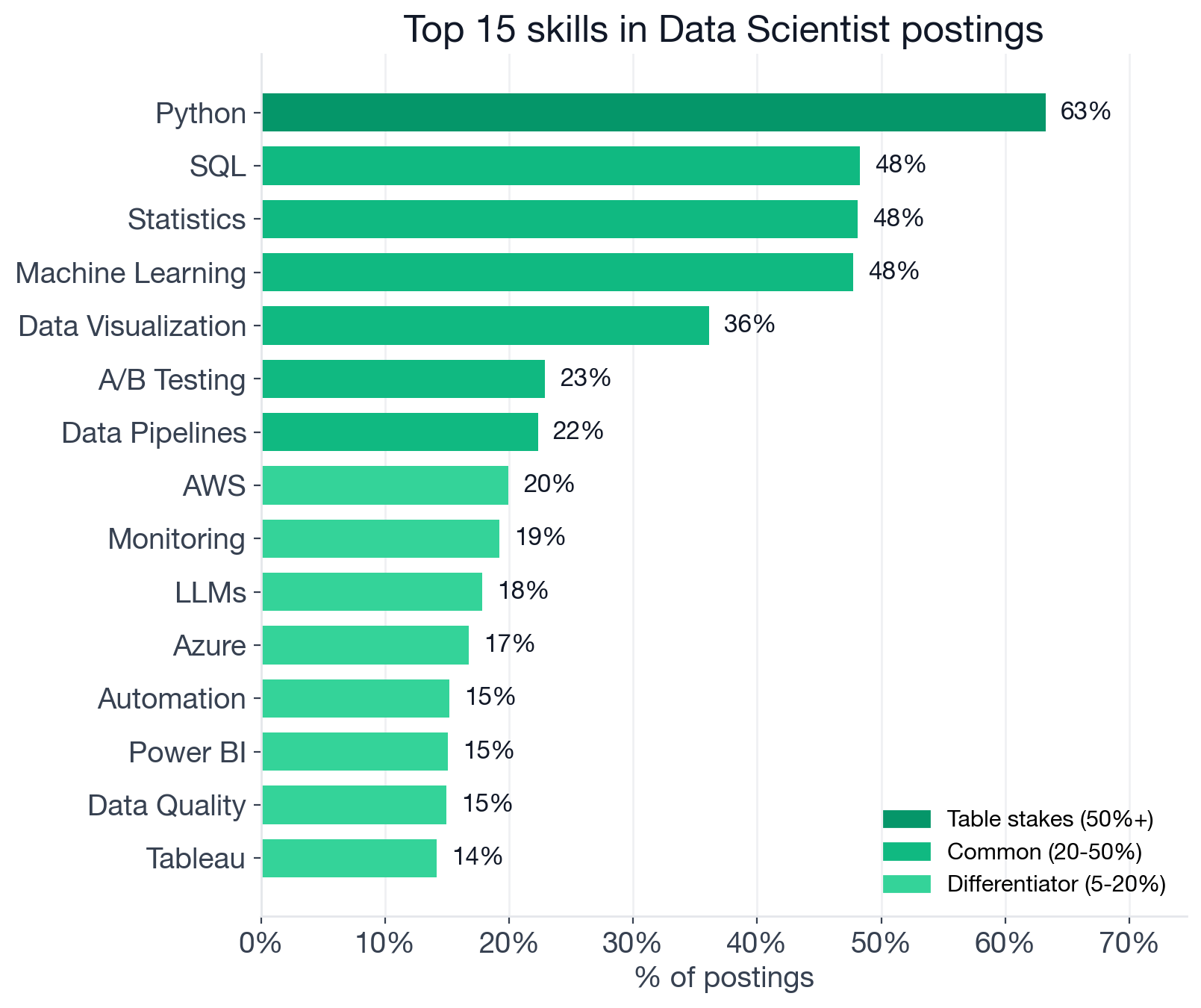
Top skills in Data Scientist postings, by share of listings that mention them. Above 50% is table stakes; 20-50% is common; 5-20% is differentiator.
Table Stakes (50%+ of postings)
Python (63.2%) is the only skill that clears the 50% bar. If your Python experience is notebook-level only, that covers many mid-level roles, but senior and ML-engineering-adjacent postings expect production-quality code: testable modules, environment management, performance-aware scripting.
Common Expectations (20-50% of postings)
Six skills cluster just below the table-stakes line:
- SQL (48.3%): Half the market still lists it explicitly. Browse Data Scientist postings that require SQL to see the range of contexts where it appears.
- Statistics (48.1%): The theoretical layer that separates a Data Scientist from an ML engineer who runs a training loop. Inference, uncertainty quantification, experimental design: the statistical layer is expected and, as the salary data shows, pays well when paired with A/B Testing.
- Machine Learning (47.7%): The umbrella ML expectation, which in most postings means "can you train, evaluate, and explain a model" rather than "can you write custom training loops from scratch."
- Data Visualization (36.1%): Communicating results to stakeholders. Most postings list it generically; Tableau (14.2%) and Power BI (15.0%) are each in the differentiator range, not common expectations.
- A/B Testing (22.9%): The highest-ROI skill to add to a Data Scientist resume that does not yet have it, based purely on the salary premium. Browse Data Scientist and A/B Testing postings to see how it appears in practice.
- Data Pipelines (22.3%): A meaningful share of postings ask for the ability to build or maintain the data feeds a model depends on, not just consume them.
Differentiators (5-20% of postings)
This tier is unusually wide for Data Scientists, a sign of how much the role fragments at the margins.
| Skill | % of postings |
|---|---|
| AWS | 19.9% |
| LLMs | 17.8% |
| Azure | 16.8% |
| Generative AI | 13.7% |
| pandas | 12.7% |
| PyTorch | 12.4% |
| TensorFlow | 12.3% |
| scikit-learn | 11.8% |
| Databricks | 11.5% |
| Deep Learning | 10.7% |
| NLP | 10.4% |
| MLOps | 9.3% |
The ML frameworks (PyTorch, TensorFlow, scikit-learn, Deep Learning) sit in the 10-12% range: present in a meaningful minority of postings, but not frequent enough to price into the baseline. Their salary signal has flattened because candidates have them; differentiation comes from what you do with them. Browse MLOps-focused Data Scientist openings if production deployment is your target specialization.
The Skill Combinations That Define Your Specialty
Two-skill co-occurrence shows which combinations appear together above chance and, more practically, which clusters define distinct flavors of the role.
| Skill pair | Postings (both) | % of market | Lift |
|---|---|---|---|
| Python + SQL | 3,270 | 42.5% | 1.39 |
| Machine Learning + Python | 3,144 | 40.9% | 1.35 |
| Python + Statistics | 3,106 | 40.4% | 1.33 |
| Machine Learning + Statistics | 2,568 | 33.4% | 1.45 |
| A/B Testing + Statistics | 1,290 | 16.8% | 1.52 |
| LLMs + Machine Learning | 1,015 | 13.2% | 1.55 |
| AWS + Azure | 907 | 11.8% | 3.53 |
| Data Visualization + Tableau | 929 | 12.1% | 2.36 |
| pandas + Python | 965 | 12.5% | 1.56 |
What each combination signals:
Machine Learning + Statistics (lift 1.45) is the core DS identity cluster: 33.4% of all postings ask for both, meaning the role expects statistical rigor to design and interpret experiments alongside the ability to train models. These are not separate skill sets in practice.
A/B Testing + Statistics (lift 1.52) marks the product-facing Data Scientist who runs controlled experiments, calculates significance, and speaks causally rather than correlationally. This is the cluster where the salary premium lives. A Data Scientist without the experimentation layer is leaving a measurable amount of compensation on the table.
LLMs + Machine Learning (lift 1.55) marks the new-wave specialization: roles that layer GenAI work on a classical ML foundation rather than replacing it. Companies writing both into the same posting expect you to understand the full stack, not just the LLM API layer.
AWS + Azure (lift 3.53) is the highest lift for a clear reason: when a company writes both cloud names, it means it. These are large enterprise roles supporting multiple business units or mid-migration between clouds. It is a narrow market but a well-paid one.
Data Visualization + Tableau (lift 2.36) signals the BI-forward Data Scientist. Tableau appearing alongside a generic visualization requirement means the role expects client-ready dashboard work, not just matplotlib in a notebook.
How Much of the 2026 Market Is Reachable From Entry Level?
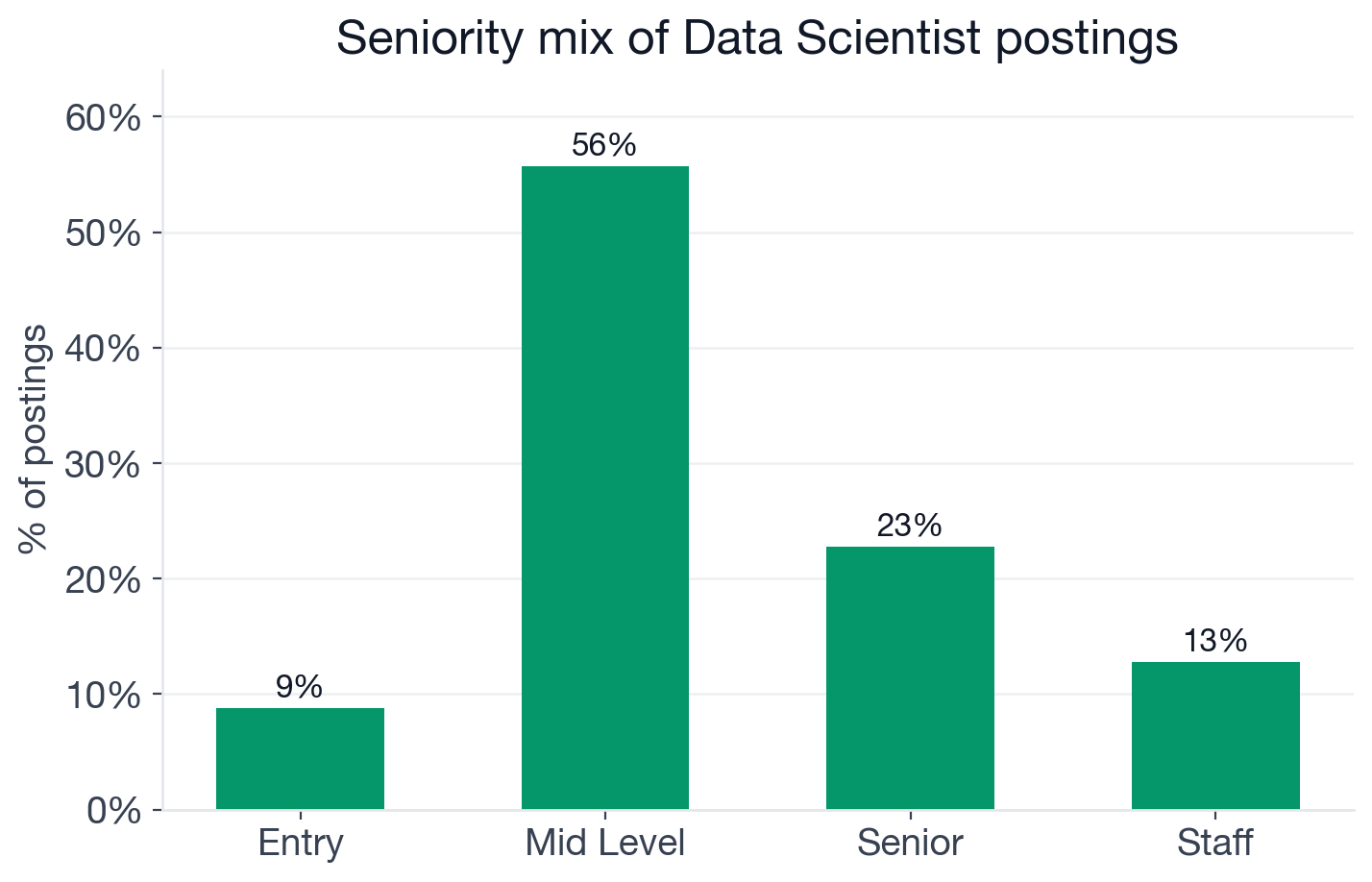
Seniority distribution of active Data Scientist postings.
Data Science entry-level sits at 8.8% (675 of 7,693), meaningfully more accessible than Data Engineer (3%) and comparable to Data Analyst. Mid-level dominates at 55.7% (4,285 postings).
The senior and staff tiers together are 35.5% of the market (1,750 senior plus 983 staff): 2,733 postings explicitly targeting experienced practitioners. That is a real growth runway on the IC track. Companies are not just looking for mid-level scientists who can execute a modeling plan. They want staff-level scientists who can define a measurement framework for a product area, set data science strategy for a business unit, or architect an ML platform a team of five can operate reliably. The operationalization skills at the top of the salary table are also the skills that unlock the staff tier.
Browse entry-level Data Scientist openings or senior Data Scientist openings to see what the current market looks like at each level.
Geography and Work Mode: More Onsite Than People Expect
The United States is the dominant market at 36.6% of postings (2,814), a higher US concentration than Data Engineer roles at 29%. India is second at 10.8% (827), followed by the UK at 4.5% (350), Canada at 3.8% (290), Germany at 2.9% (226), and Singapore at 2.8% (214).
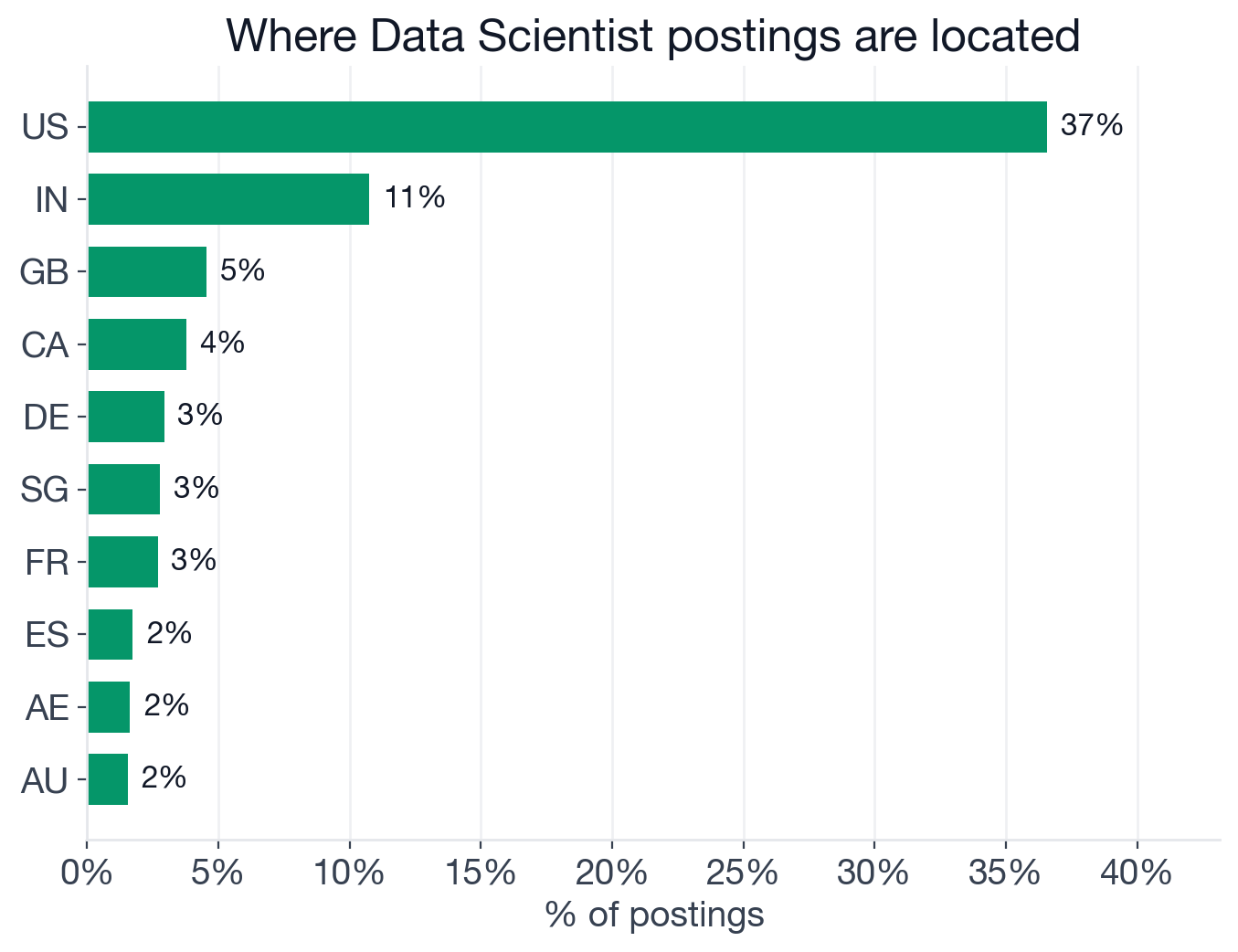
Top countries by share of active Data Scientist postings.
The remote picture is tighter than many practitioners expect.
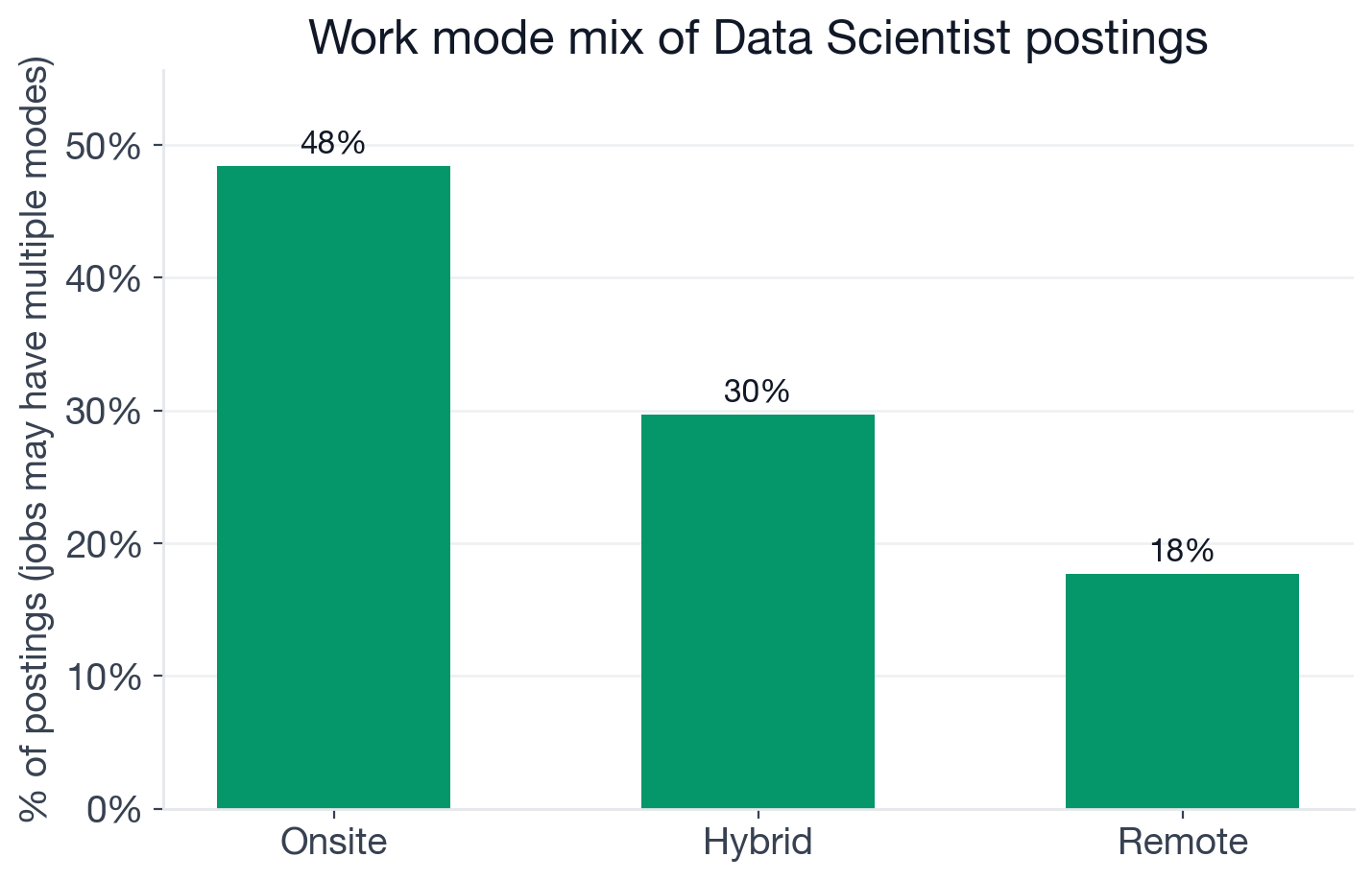
Share of Data Scientist postings tagged with each work mode. Some postings carry multiple tags, so percentages can exceed the non-unknown total.
- Onsite: 48.4% (3,725 postings)
- Hybrid: 29.7% (2,282)
- Remote: 17.7% (1,362): fully-remote Data Scientist openings
The 17.7% remote share is notably lower than for Data Engineer roles (27%). Data Scientists are expected to interact heavily with product managers, domain experts, and stakeholders: many companies have concluded that collaboration quality drops when those conversations happen asynchronously. Healthcare, pharma, and government, which dominate this role's employer mix, also default strongly to onsite or hybrid.
Who Is Hiring Data Scientists in 2026?
The top hiring companies in this dataset skew heavily toward healthcare, pharma, defense, and energy, a different profile from the pure-tech roster many practitioners expect when they picture Data Scientist hiring.
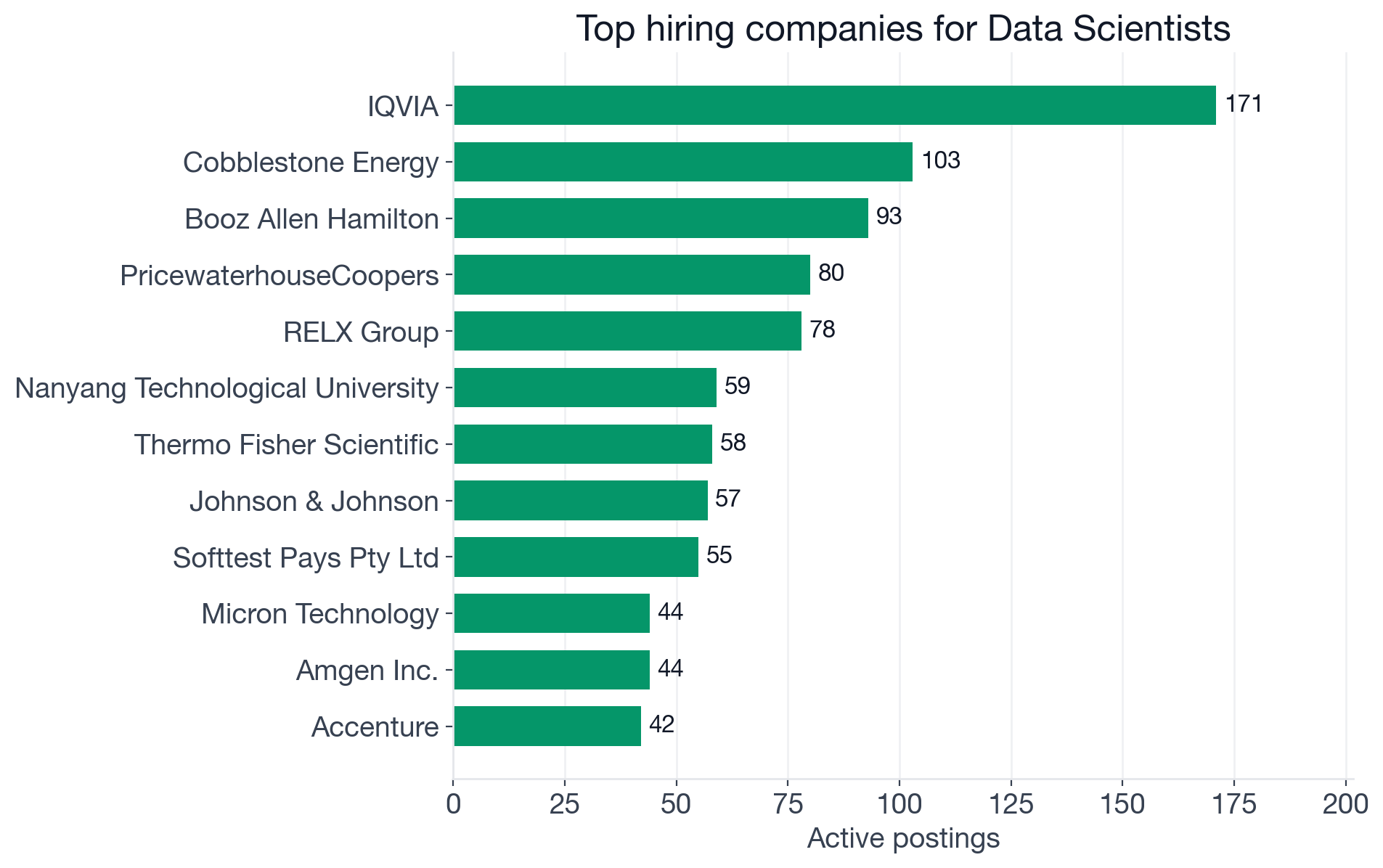
Top companies by active Data Scientist postings (distinct openings).
| Company | Postings | Sector |
|---|---|---|
| IQVIA | 171 | Healthcare data and analytics |
| Cobblestone Energy | 103 | Energy trading / commodities |
| Booz Allen Hamilton | 93 | Defense and government consulting |
| PricewaterhouseCoopers | 80 | Big Four consulting |
| RELX Group | 78 | Data, analytics and publishing |
| Nanyang Technological University | 59 | Research (Singapore) |
| Thermo Fisher Scientific | 58 | Life sciences |
| Johnson and Johnson | 57 | Pharma |
| Micron Technology | 44 | Semiconductors |
| Amgen | 44 | Biotech |
| Accenture | 42 | Consulting |
| Royal Bank of Canada | 36 | Banking |
IQVIA at 171 postings reflects how central data science has become to clinical trials, real-world evidence, and drug commercialization. Cobblestone Energy at 103 is a commodity trading firm that runs quantitative models on energy markets: high-intensity, production-grade DS work. The healthcare and pharma cluster (RELX, Thermo Fisher, J&J, Amgen) accounts for a large share of the top 12, consistent with healthcare being the second-largest identified industry in the dataset.
The absence of hyperscalers near the top of this list is a structural feature of job board data: large tech companies fill many Data Scientist roles through internal referral and proprietary recruiting channels, posting fewer openings publicly. The companies ranking highest here predominantly use public-posting workflows as a primary channel.
For company-specific interview prep, the InterviewStack.io preparation guides cover the DS interview formats at major employers.
How to Use This in Your Job Search
Build the foundation before specializing. Python plus SQL plus Statistics is the base that two-thirds of the market filters on. Not statistical theory for its own sake: the Statistics expectation means knowing when to use a t-test versus a chi-square, how to set a significance threshold, and how to explain a p-value to a product manager who does not care about the math. Browse current Data Scientist openings to calibrate what the actual postings ask for before narrowing by specialization.
Add the experimentation layer next. The salary data makes a concrete argument: if you already have ML fundamentals, the highest-ROI skills to add are A/B Testing and MLOps, in that order. A/B Testing moves you toward business-impact measurement; MLOps moves you toward the production deployments that make a model actually useful. Both carry premiums that the model-building frameworks do not. The question bank has dedicated topics for hypothesis testing, power analysis, and causal inference, which are the statistical foundations that show up in Data Scientist interviews across all company types.
Take the dbt signal seriously. The $161,500 US median for dbt is the largest premium among commonly required skills in this analysis. It signals where enterprise Data Science is moving: closer integration with the analytics engineering layer, shared ownership of data models, and the expectation that a Data Scientist can write and review dbt models alongside DE teammates. If your company runs a dbt stack, learning it is likely the highest-leverage upskilling move available to you right now.
Practice the full round before applying broadly. AI mock interviews let you simulate the case-study, SQL design, and statistical-reasoning rounds that appear in Data Scientist interviews at most mid-to-large companies. Our interactive courses cover the statistical and ML foundations in depth. Once the skills are in place, use the job board's skill filters to find postings where you are genuinely competitive from the first screen: Python and SQL for the broadest sweep, or MLOps-specific openings if production deployment is your target.
FAQ
Q. What foundational skills do Data Scientist roles require in 2026?
Python is the only table-stakes skill for Data Scientists in 2026, appearing in 63.2% of active postings (4,865 of 7,693 analyzed). SQL (48.3%), Statistics (48.1%), and Machine Learning (47.7%) form a dense common tier just below table stakes, each appearing in roughly half of all postings. A resume without Python is filtered out by two-thirds of the market before a recruiter reads a line.
Q. What is the median Data Scientist salary in 2026?
The median US base salary is $125,000 across 1,504 Data Scientist postings with salary disclosed. That figure is base only: equity, bonuses, and sign-on are not captured in posting data, so total compensation at top employers runs meaningfully higher. Differentiator skills like dbt, A/B Testing, and MLOps sit $16K to $36K above that baseline.
Q. Which Data Scientist skills pay the highest salary premium?
Among US postings, dbt (a SQL transformation framework for modern data warehouses) commands the largest premium among commonly required skills covered here at $161,500 median (n=56), about $36,500 above the $125,000 role baseline. MLflow follows at $154,000 (n=36, +$29K), A/B Testing at $152,000 (n=467, +$27K), and MLOps at $141,200 (n=138, +$16K). In contrast, PyTorch ($125,000, n=187) and TensorFlow ($122,000, n=181) sit at or below the role median despite being the framework skills most associated with Data Science.
Q. How entry-level-friendly is Data Science hiring in 2026?
More accessible than Data Engineer, but still selective: 8.8% of Data Scientist postings are explicitly entry-level (675 of 7,693), comparable to Data Analyst hiring. Mid-level dominates at 55.7% of postings (4,285). Senior and staff roles together account for 35.5% of the market (2,733 postings), confirming meaningful IC career runway above the mid-level band.
Q. What is the dominant Data Scientist skill stack in 2026?
Python and SQL co-occur in 3,270 postings (42.5% of the market) with a lift of 1.39, forming the foundation. The experimentation cluster pairs A/B Testing with Statistics at lift 1.52 (1,290 postings), signaling that hypothesis-driven experimentation is a core DS workflow alongside model-building. LLMs plus Machine Learning show a lift of 1.55 (1,015 postings), marking the subset of roles where GenAI work layers on top of classical ML.
Q. Where are Data Scientist jobs located, and how remote-friendly are they?
The United States is the largest market at 36.6% of postings (2,814), followed by India at 10.8% (827), UK at 4.5% (350), Canada at 3.8% (290), and Germany at 2.9% (226). Work mode skews toward onsite: 48.4% of postings are tagged onsite, 29.7% hybrid, and 17.7% fully remote. The remote share is lower than for Data Engineer roles, reflecting the collaboration and stakeholder-communication demands of analytical work.
Q. How are AI and generative AI skills valued for Data Scientists in 2026?
About 17.8% of Data Scientist postings explicitly require LLM experience and 13.7% require Generative AI, totaling roughly 21% for new-wave AI. These figures measure jobs where you are expected to build with LLMs, not ambient tool usage. Surveys from Stack Overflow (84% of developers using or planning to use AI tools in 2025) and JetBrains (90% of developers regularly using at least one AI tool at work in 2026) indicate AI coding assistants are already a baseline expectation across all developer and data roles. A Data Scientist who is not using AI tools in their daily notebook and scripting workflows is increasingly the outlier.
What the Market Is Actually Rewarding
The ML frameworks are not going away. Python, PyTorch, TensorFlow, and scikit-learn will keep showing up in Data Scientist postings because they are the tools the work gets done with. But 2026 hiring has clarified what it actually pays for: the layer between model and outcome. A/B Testing, MLOps, experiment tracking, and SQL-native data modeling consistently command premiums that the frameworks do not, because those skills are harder to acquire on a weekend and harder to fake in an interview.
For practitioners building toward the next level, the sequencing the data suggests is foundations first, experimentation second, production operations third. The staff tier (12.8% of all postings) is real and growing, and it rewards the same pattern: what matters is not the model you can build, but the measurement framework you can own.
Topics
Ready to practice?
Put what you've learned into practice with AI mock interviews and structured preparation guides.