The Architecture Is the Easy Part
A prepared DevOps engineer can sketch a CI/CD pipeline in the first five minutes: PR trigger, build, unit tests, artifact, deploy, promote. The interviewer expects this. The design sketch is the opening, not the evaluation. What comes after it is where the score is decided.
This walkthrough follows a real 30-minute mid-level interview on continuous integration and delivery pipelines, structured against the blueprint the AI mock interviewer uses at InterviewStack.io. The scenario is a team shipping six containerized microservices to Kubernetes on AWS, releasing manually every one to two weeks. Four follow-up questions determine whether the candidate actually understands the system or just its shape.
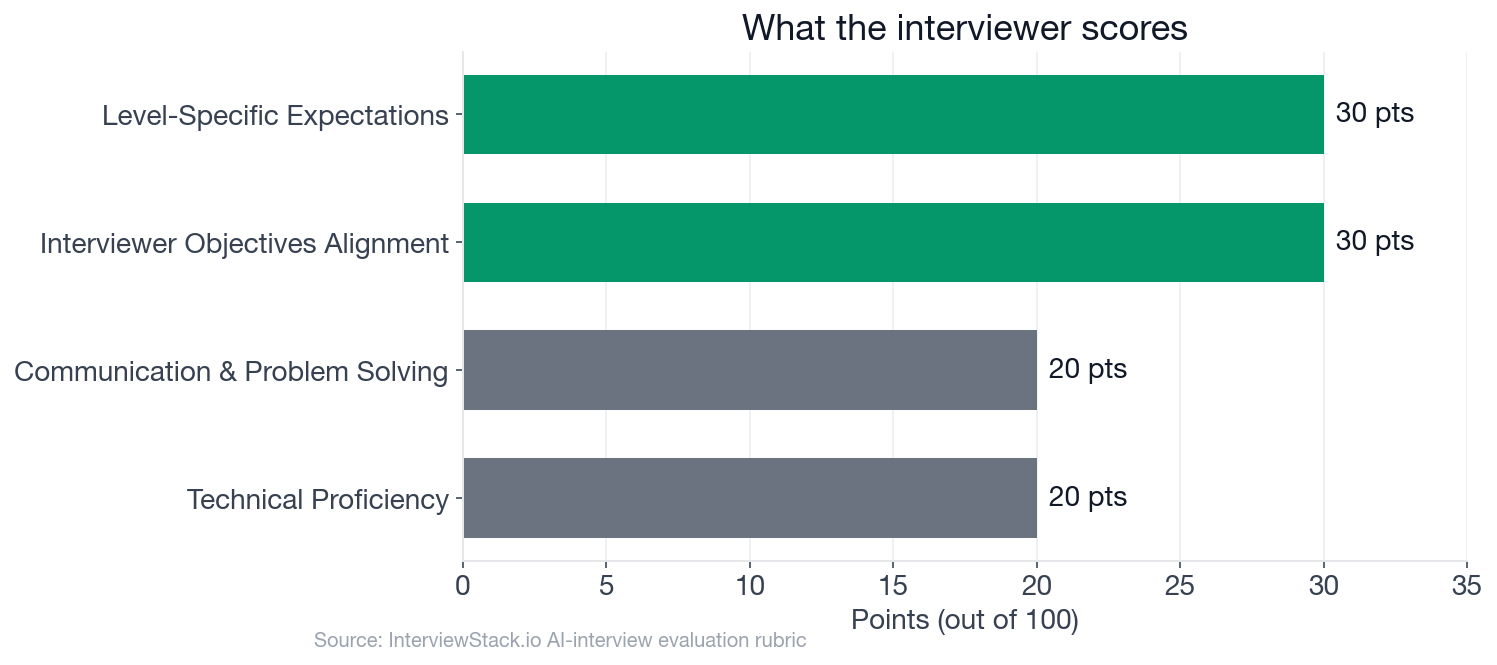
The rubric weights two judgment dimensions above technical recall.
Key Findings
- The interview runs 30 minutes across 3 phases: pipeline architecture (0-10 min), quality gates and deployment safety (10-22 min), and security and scalability (22-30 min).
- 60 of 100 rubric points come from Interviewer Objectives Alignment (30 pts) and Level-Specific Expectations (30 pts): judgment and depth, not recall.
- Phase 2 spans 12 minutes, the longest phase, and is where most mid-level candidates leave the most ground.
- Phase 1 has 5 checklist items including immutable artifact versioning (commit-SHA or semver image tags) and separate PR vs post-merge triggers, both commonly understated in opening answers.
- Phase 3 tests 5 operational maturity items: secrets handling, branch protection, pipeline observability, build optimization, and pipeline-as-code maintainability.
- Mid-level candidates are expected to surface realistic failure modes (flaky tests, environment drift, unhealthy rollouts) without deep prompting.
- Technical Proficiency and Communication together account for the remaining 40 of 100 rubric points.
What the DevOps Engineer CI/CD Pipeline Interview Actually Opens With
The interview question
Your team owns a customer-facing web application made up of 6 containerized microservices deployed to Kubernetes in AWS. Engineers merge to GitHub daily, and releases currently happen manually every 1-2 weeks, which has led to inconsistent deployments, flaky rollouts, and slow recovery when issues reach production.
The team wants a CI/CD pipeline that: runs on every pull request and on merges to main; builds and tests both application code and infrastructure-as-code changes; produces versioned deployable artifacts; promotes changes through dev, staging, and production; and reduces failed deployments while still allowing frequent releases. The company already uses GitHub, Kubernetes, Docker, Terraform, and a cloud secret manager.
How would you design the CI/CD pipeline for this team?
The interviewer's objectives go deeper than a diagram. They want to know whether you can translate the team's reliability problems into concrete pipeline stages, whether you reason about speed vs safety trade-offs without being prompted, and whether you recognize the failure modes this team is already experiencing. Most candidates address the first part. The follow-ups test the second and third.
The Walkthrough: Four Follow-Ups That Decide the Score
Turn 1: PR Validation Speed vs Confidence
Interviewer: "If the team tells you pull request validation is taking too long and developers are bypassing it, how would you restructure the pipeline without losing confidence in changes?"
Turn 2: Staging Passes, Production Breaks
Interviewer: "Suppose a deployment passes in staging but causes elevated error rates in production after 5 minutes. How should the pipeline and release process respond?"
Turn 3: Secrets and the Trust Boundary
Interviewer: "How would you manage secrets and other sensitive configuration in the pipeline so builds and deployments remain secure?"
Turn 4: Avoiding Unnecessary Rebuilds Across Services
Interviewer: "If one service changes frequently while the others are stable, how would your design avoid rebuilding and redeploying everything unnecessarily?"
Spotting Mistakes on the Page Is the Easy Part
Reading a coached walkthrough is a different skill from performing in one. At minute 18, when you have already described the full pipeline architecture and the interviewer pivots to a staging-to-production divergence scenario you weren't anticipating, "roll back" feels like a complete answer. The post-deployment health-check gate and the rollback trigger signal are the details that slip. That gap only closes through reps with unscripted follow-ups.
The Complete 30-Minute Blueprint
Below is the blueprint a strong candidate hits across the full session, and the exact structure the AI mock interview tracks you against in real time.
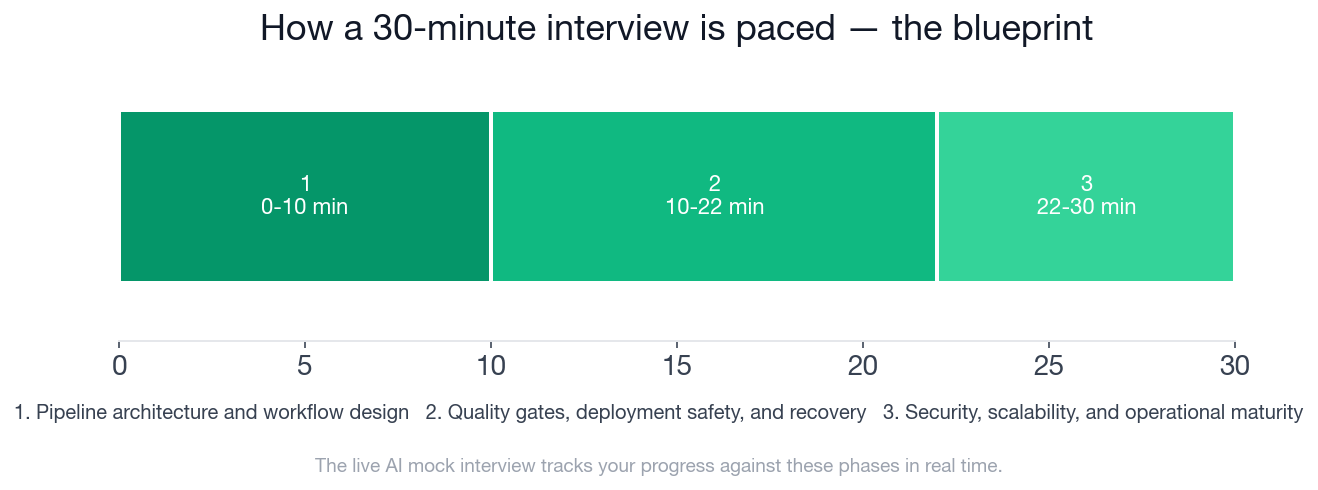
The three phases map to three distinct modes of questioning: design, safety, and operational maturity.
- ✓Outlines separate PR and post-merge pipelines or equivalent trigger strategy
- ✓Includes build, test, artifact publishing, and deployment stages in a logical order
- ✓Describes promotion through dev, staging, and production rather than rebuilding differently per environment
- ✓Uses immutable versioned artifacts such as container images tagged by commit SHA, semver, or release identifier
- ✓Addresses how infrastructure changes are validated before apply, at least via fmt/validate/plan and controlled apply
- ✓Differentiates faster PR checks from slower post-merge or pre-prod validation
- ✓Places unit tests early and reserves heavier integration/end-to-end tests for later stages or targeted runs
- ✓Chooses a deployment approach such as rolling, blue-green, or canary and gives a practical reason for it
- ✓Explains what signals gate promotion or trigger rollback, such as deployment health, smoke tests, error rates, or latency thresholds
- ✓Describes a concrete rollback or roll-forward approach for both application and infrastructure changes
- ✓Keeps secrets out of source control and uses short-lived credentials or managed secret retrieval in CI/CD
- ✓Mentions branch protection, environment approvals for production or equivalent release controls
- ✓Describes how pipeline status, test results, and deployment outcomes are surfaced to engineers
- ✓Suggests a practical optimization such as path-based builds, service-scoped pipelines, caching, or parallelized jobs
- ✓Explains pipeline-as-code maintainability practices such as reusable workflows, templates, or modularization
Practice the Full Session
The blueprint above is what the AI mock interview for this topic tracks in real time: as you respond to each follow-up, it marks checklist items against the phases, then scores your session across all four rubric dimensions at the end. It is the closest equivalent to a live unscripted interview you can get before the real one.
If you want to drill specific questions before running the full session, the CI/CD pipeline question bank covers deployment safety, rollback strategies, secrets handling, and pipeline optimization in depth.
FAQ
Q. How long is a DevOps Engineer CI/CD pipeline design interview?
The blueprint runs 30 minutes across 3 phases: pipeline architecture and workflow design (0-10 min), quality gates, deployment safety, and recovery (10-22 min), and security, scalability, and operational maturity (22-30 min). The middle phase is the longest at 12 minutes and is where most mid-level depth is tested.
Q. What rubric dimensions matter most in a CI/CD pipeline interview?
The 100-point rubric splits as Interviewer Objectives Alignment (30 pts), Level-Specific Expectations (30 pts), Technical Proficiency (20 pts), and Communication and Problem Solving (20 pts). The first two dimensions together account for 60 points and measure judgment and depth, not just recall.
Q. What deployment pattern should I recommend for Kubernetes in a mid-level CI/CD interview?
Rolling updates are the safe baseline for Kubernetes, but a stronger answer explains the trade-off: rolling gives zero-downtime without extra infrastructure, while canary or blue-green deployments offer more precise traffic control and safer rollback. Giving a reason tied to the scenario (six services, daily merges) is what earns points at the mid-level bar.
Q. How do candidates typically lose points on secrets management in CI/CD interviews?
The most common gap is describing a solution (use a vault, reference environment variables) without addressing the security model: where credentials originate, how long they live, and what the trust boundary is in the CI/CD executor. Mid-level candidates are expected to mention least-privilege access, short-lived credentials or OIDC federation, and protection against secrets appearing in logs.
Q. What does the mid-level bar look like for CI/CD pipeline design?
A mid-level DevOps Engineer should design a workable pipeline end to end and explain stage ordering and environment promotion without deep prompting. They are expected to recognize realistic failure modes such as flaky tests, environment drift, and unhealthy Kubernetes rollouts, and propose mitigations without being led there.
Q. How should I handle the PR-feedback-speed versus test-coverage trade-off in an interview?
The expected approach is to separate PR checks from post-merge validation: run fast unit tests and linting on every PR, move slower integration and end-to-end tests to post-merge or pre-production stages, and add parallelization and layer caching to keep PR feedback under a few minutes. The key signal is knowing which tests to gate the PR on versus which to run later.
Where to Start
Start with Phase 2. It runs 12 minutes in a 30-minute session, and it is where the questions shift from "what would you design" to "what would actually happen when this breaks." Drill the deployment safety and recovery scenarios in the question bank, then run the full AI mock session to practice answering them in sequence, under time, without knowing which follow-up is coming next.
Topics
Ready to practice?
Put what you've learned into practice with AI mock interviews and structured preparation guides.