Strong Offline Accuracy Is Not the Same as Ready to Launch
The model hits 97% offline accuracy. Every validation chart looks clean. A week after launch, the operations team files a ticket: reviewer queue volume is up 3x and quality is inconsistent across regions. The engineer on the call is not ready to answer why.
This is the opening scenario of how a leading tech company interviews mid-level Machine Learning Engineers on model evaluation. The interview is not testing whether you can define precision and recall. It is testing whether you recognized from the first minute that accuracy was the wrong goal. Based on the rubric that drives the AI mock interview for this topic, 60 of 100 points hinge on the two dimensions that reward problem framing and level-appropriate judgment, not implementation detail.
Key Findings
- 60 of 100 rubric points go to Interviewer Objectives Alignment (30 pts) and Level-Specific Expectations (30 pts); Technical Proficiency and Communication split the remaining 40 pts at 20 pts each.
- Phase 1 (0-10 min) carries 5 checklist items, all centered on rejecting accuracy and proposing metrics grounded in reviewer capacity and business cost.
- Mid-level candidates are expected to independently identify that accuracy is insufficient and propose at least 1 threshold-free metric plus 1 operating-point metric tied to business cost.
- Phase 2 (10-22 min, 12 minutes) covers 5 validation checklist items including leakage detection, temporal splits, and segment-level coverage.
- Phase 3 (22-30 min, 8 minutes) includes 5 launch-readiness checklist items: rollout strategy, production monitors, alert conditions, rollback triggers, and stakeholder reporting.
- A random train/val/test split on this scenario creates 2 distinct leakage risks: temporal drift and seller-group correlation, both of which inflate offline metrics.
- PR AUC is the preferred threshold-free metric for imbalanced classifiers; the blueprint also checks for a capacity-tied operating-point metric paired with it.
The Machine Learning Engineer Model Evaluation Interview Question
The interview question
You are joining a team at a large consumer tech company that ranks and filters millions of user-generated listings each day. A new binary classification model predicts whether a listing should be sent to manual review for potential policy violations before it goes live. Only a small fraction of listings are truly violating, reviewer capacity is limited, and sending too many clean listings to review creates operational cost and delays for good sellers. Missing violating listings creates user trust and policy risk. The current model shows strong offline accuracy, but after a recent launch the operations team reported worse-than-expected reviewer load and inconsistent quality across regions.
You have access to historical labeled data, model scores, reviewer outcomes, listing metadata, and post-launch production logs.
How would you evaluate and validate this model end to end, and how would you determine whether it is ready to launch or needs changes?
The interviewer is probing whether you can design a practical evaluation strategy for a real production system, justify metric choices against business risk rather than benchmark convention, diagnose model failure modes including class imbalance, leakage, and distribution shift, and translate offline validation into concrete launch criteria.
The Walkthrough: Turn by Turn
Turn 1: Choosing the Right Metrics
Interviewer: "What offline metrics would you choose here, and how would you decide between precision, recall, F1, ROC AUC, PR AUC, calibration, and threshold-based business metrics?"
Turn 2: Designing the Validation Split
Interviewer: "How would you split the data for validation and testing if listing behavior changes over time and some sellers submit many related listings?"
Turn 3: Diagnosing the Offline-Online Gap
Interviewer: "Suppose offline metrics look strong but reviewer load spikes after launch. What hypotheses would you investigate first, and how would you test them?"
Turn 4: Production Monitoring and Alerts
Interviewer: "What would you monitor in production to catch data drift, concept drift, and silent failures, and what alerts would you set?"
Watching Sam's mistakes on screen feels obvious in hindsight. But in a live 30-minute interview you have no coaching, no pause button, and an interviewer who will not correct your framing. The skill is not knowing what PR AUC is. It is structuring your thinking fast enough to get the framing right before the first follow-up arrives.
The Complete Blueprint
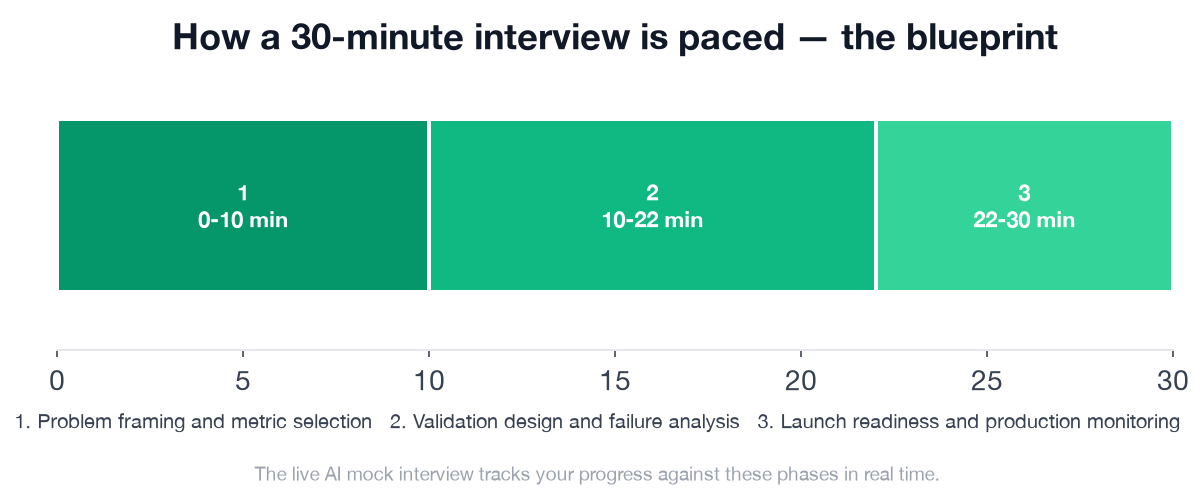 A well-paced 30-minute model evaluation interview runs three phases; the framing phase (0-10 min) carries 5 checklist items that set the foundation for everything that follows.
A well-paced 30-minute model evaluation interview runs three phases; the framing phase (0-10 min) carries 5 checklist items that set the foundation for everything that follows.
This is the blueprint a strong candidate hits across the full 30 minutes, and the exact structure the AI mock interview tracks you against in real time.
- ✓Asks or states key assumptions about prevalence of violating listings, reviewer capacity, and cost of false positives vs false negatives
- ✓Rejects accuracy as primary success metric
- ✓Proposes suitable metrics such as precision, recall, PR AUC, ROC AUC, F1 or cost-weighted metrics, with justification
- ✓Mentions evaluating multiple operating thresholds rather than a single default threshold
- ✓Recognizes calibration or score reliability as relevant if decisions depend on score cutoffs or capacity planning
- ✓Proposes a split strategy that accounts for temporal drift and correlated listings or seller overlap
- ✓Preserves a final untouched test set or equivalent holdout for launch decisions
- ✓Discusses stratification or segment coverage for rare positives and important regions
- ✓Identifies plausible offline-online gap causes such as calibration drift, base rate shift, pipeline mismatch, label delay, logging bugs, or threshold misconfiguration
- ✓Suggests concrete checks such as comparing score distributions, confusion matrices by segment, feature drift, label quality audits, and train-vs-validation learning behavior
- ✓Defines launch criteria using both model quality and operational metrics such as reviewer queue volume or time-to-listing
- ✓Describes a limited-risk rollout approach such as shadow mode, canary, or champion-challenger comparison
- ✓Proposes production monitors for prediction distribution, input feature drift, calibration or realized precision/recall when labels arrive, and segment-level performance
- ✓Includes clear alert or rollback conditions for spikes in false positives, reviewer load, or degraded segment performance
- ✓Communicates how results would be reported to both technical and business stakeholders
Practice This Interview, Not Just These Answers
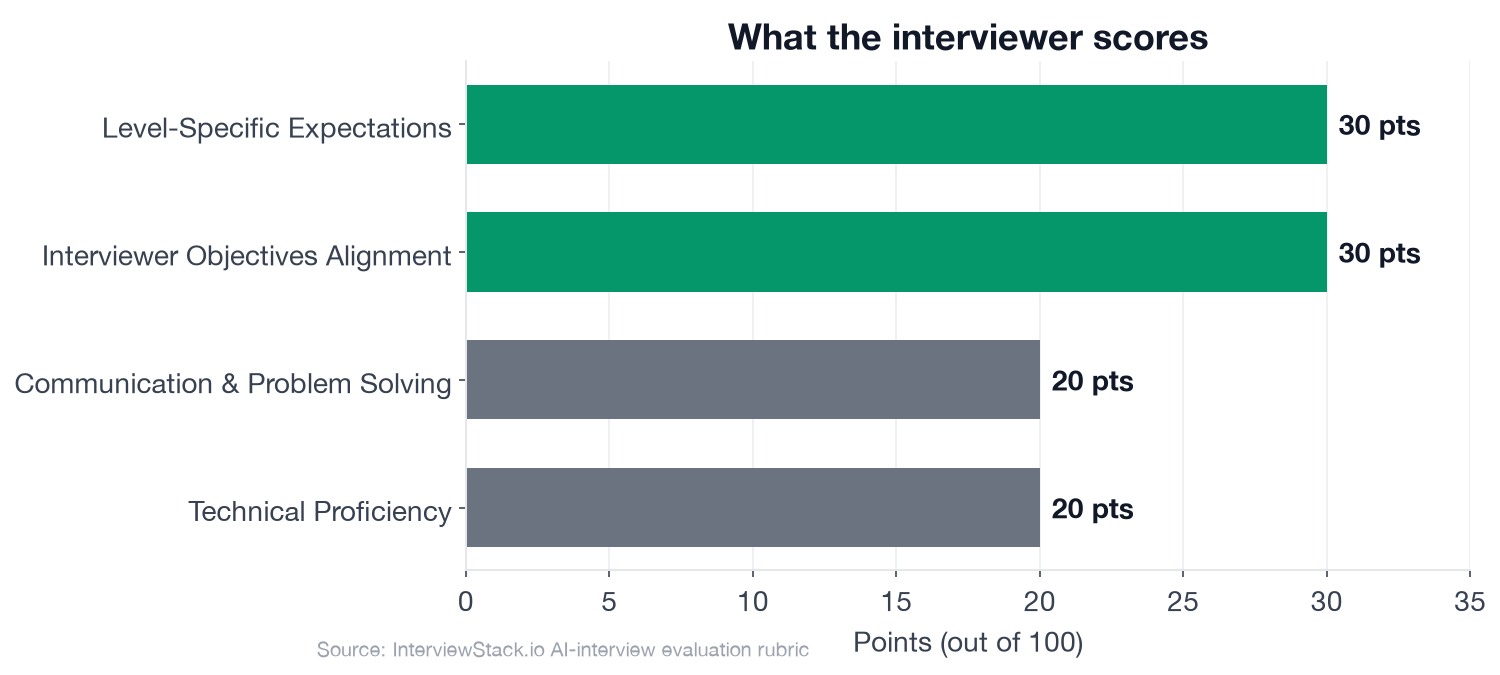 Rubric breakdown: 60 points go to Objectives Alignment and Level-Specific Expectations; knowing the technical definitions earns only 20.
Rubric breakdown: 60 points go to Objectives Alignment and Level-Specific Expectations; knowing the technical definitions earns only 20.
The walkthrough above covers 4 of 6 possible follow-ups. The AI mock interview will probe different turns, adapt in real time to what you say, and score you across all four rubric dimensions. There is no script to rehearse.
Start the Machine Learning Engineer model evaluation interview now and get scored feedback within minutes. If you want to drill individual questions before your first session, the Machine Learning Engineer model evaluation question bank covers the full topic space.
Looking for structured concept prep? InterviewStack's interactive courses include ML foundations covering evaluation, validation, and production monitoring in depth. You can also browse open Machine Learning Engineer roles to see which evaluation and monitoring skills companies are hiring for right now.
FAQ
Q. What metrics should a Machine Learning Engineer use for an imbalanced binary classifier?
For an imbalanced classifier like a policy-violation detector, reject accuracy as the primary metric. Precision-Recall AUC (PR AUC) is more informative than ROC AUC when positives are rare. Pair a threshold-free metric (PR AUC) with a threshold-based metric tied to business cost, such as precision at the reviewer capacity constraint or a cost-weighted F-beta score.
Q. How should ML engineers split data for time-series validation?
Use a temporal split that preserves data ordering: training covers the earlier time window, validation covers a middle window, and holdout covers the most recent period. Group by seller or listing source within each split to prevent correlated examples from crossing boundaries and creating leakage. Stratify across regions if rare positive classes are unevenly distributed.
Q. What causes the offline-online performance gap in ML models?
Common causes include calibration drift (scores that ranked correctly offline do not map to reliable probabilities in production), base rate shift (violation rate in live traffic differs from training distribution), pipeline mismatch (feature computation in serving differs from training), label delay (labels arrive late), and threshold misconfiguration (offline threshold applied without recalibration at the live operating point).
Q. How do you choose a classification threshold when reviewer capacity is limited?
Map capacity to a precision constraint first: if reviewers can handle N listings per day, the threshold must control false positive volume within that budget. Plot the precision-recall curve and identify the operating point where precision meets the capacity requirement, then check whether recall at that point is acceptable for policy risk. Explicit cost weighting of false negatives (trust risk) versus false positives (operational cost) gives you a principled threshold instead of a default 0.5.
Q. What should Machine Learning Engineers monitor in production for model drift?
Monitor prediction score distribution (compare to offline baseline), input feature distributions for data drift, realized precision and recall as reviewer labels accumulate, segment-level performance by region and seller type, and reviewer queue volume as a leading operational signal. Set alert thresholds on false positive rate spikes and queue volume exceedances, with a rollback condition if precision falls below the reviewer capacity constraint.
Q. How is a Machine Learning Engineer model evaluation interview scored?
The rubric allocates 30 points to Interviewer Objectives Alignment (metric selection, validation design, debugging, launch readiness), 30 points to Level-Specific Expectations (independently reject accuracy, identify leakage risks, outline a pragmatic launch plan), 20 points to Technical Proficiency, and 20 points to Communication and Problem Solving. Total: 100 points across 4 dimensions.
Q. What phases does a 30-minute ML engineer model evaluation interview cover?
A well-run 30-minute model evaluation interview covers three phases: Problem framing and metric selection (0-10 min) where the candidate establishes business risk and chooses metrics; Validation design and failure analysis (10-22 min) covering split strategy, leakage detection, and debugging; and Launch readiness and production monitoring (22-30 min) covering rollout strategy, alerts, and stakeholder reporting.
Where the Score Actually Comes From
The rubric puts 60 points on framing and level-appropriate judgment. The candidates who clear mid-level model evaluation interviews do not know more definitions: they start with the right question ("what are we actually optimizing for, and what does the operational constraint say about that?"), build the evaluation strategy from there, and stay in diagnostic mode when something goes wrong. That instinct is what live practice builds. The question bank covers the topic in depth; the AI interview is where you develop the instinct.
Topics
Ready to practice?
Put what you've learned into practice with AI mock interviews and structured preparation guides.