Short-Term Engagement Was Never the Point
A large consumer video platform wants to ship a new home feed ranking model. It is expected to lift short-term engagement by showing more personalized recommendations. It is also expensive to serve, and it could change outcomes for the creators whose content gets surfaced less. Product leadership wants a fast answer.
That is the scenario a mid-level Research Scientist candidate gets handed in this 30-minute mock interview, built on the same blueprint InterviewStack.io's AI interviewer uses to score real practice sessions. Nothing in the prompt says "optimize for engagement." It says engagement will likely rise and ecosystem health might not. Most candidates hear the first half and design an experiment for it. The interview is actually scoring whether you hold both halves at once.
Key Findings
- The interview runs 30 minutes across 3 phases: framing (0-10 min), statistical rigor (10-22 min), and decision-making (22-30 min).
- 60 of 100 rubric points sit in Interviewer Objectives Alignment (30) and Level-Specific Expectations (30), both judgment dimensions, not stats trivia.
- Phase 3 packs 5 checklist items into just 8 minutes, the tightest ratio of the three phases.
- Candidates are expected to name at least 2 of 5 listed validity threats (sample ratio mismatch, instrumentation bias, novelty effects, triggered-analysis pitfalls, contamination) unprompted.
- Two of the 4 forbidden skills are SQL query writing and whiteboard coding algorithms; this is a design and judgment interview, not a coding test.
- Only one checklist item across all 3 phases requires treating creator ecosystem health as a hard guardrail rather than a metric to "keep an eye on."
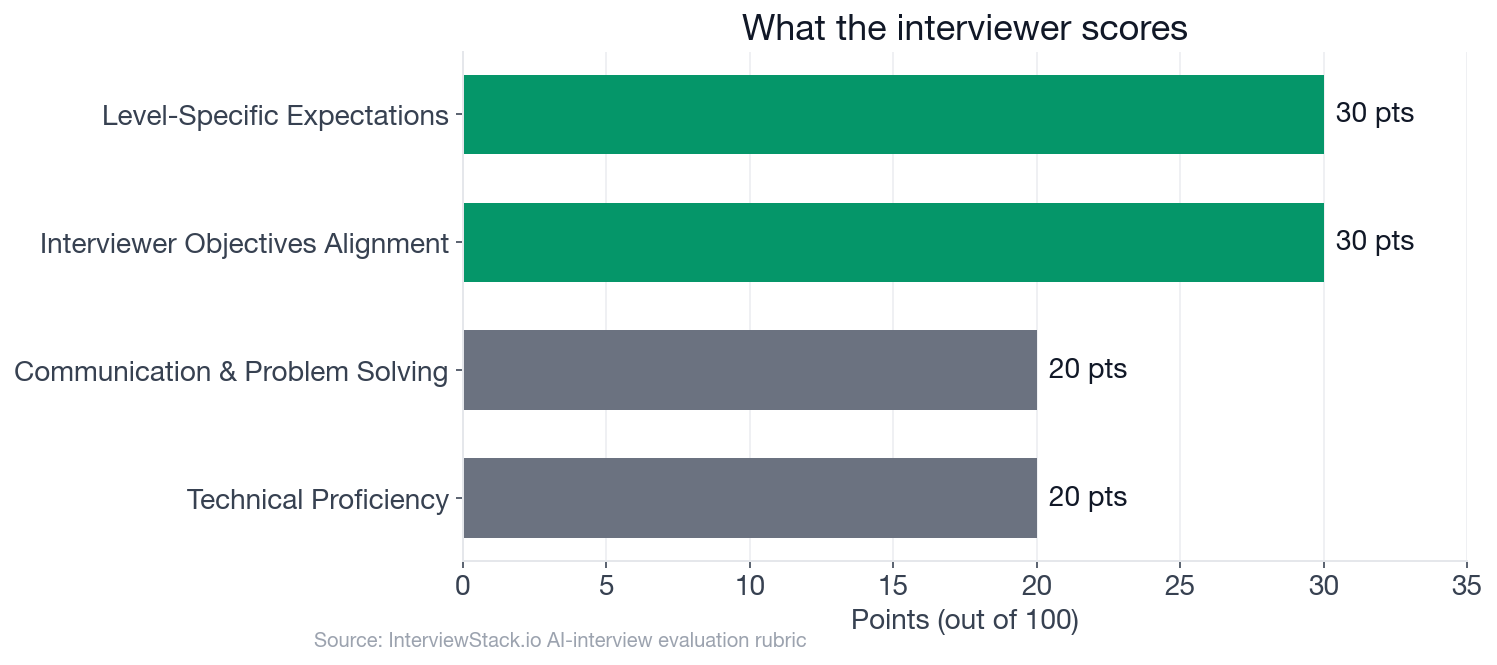 The two framing-and-judgment dimensions carry 60 of the 100 points, more than technical accuracy and communication combined.
The two framing-and-judgment dimensions carry 60 of the 100 points, more than technical accuracy and communication combined.
The interview question
Your team at a large consumer video platform is considering launching a new home feed ranking model that is expected to increase short-term engagement by showing more highly personalized recommendations. Product leadership wants to validate the change quickly because the model is expensive to serve and could also affect creator ecosystem outcomes over time. Assume the change can be randomized at the user level in the app for users who open the home feed during the experiment window.
How would you design an experiment and decision framework to evaluate whether this new ranking model should launch?
The interviewer is really probing something narrower than "do you know A/B testing": can you translate a vague product ask into a rigorous plan, reason correctly about power, peeking, and multiple-comparison risk, and communicate a launch recommendation that a large tech company can actually stand behind. Getting the statistics right and missing the ecosystem framing still fails the objective.
Inside a Research Scientist Experimentation Interview
We picked four of the six follow-ups the AI interviewer can ask on this topic, chosen to span all three scoring phases. A consistent candidate, Devon, walks through each one below: a common mistake, what it costs, and the stronger move.
Turn 1: Metric and Guardrails
Interviewer: "What would you choose as the primary success metric, and what guardrails would you put in place given the risk of improving engagement while harming longer-term ecosystem health?"
Turn 2: Interim Reads Without Inflating False Positives
Interviewer: "Suppose leadership wants to look at results every day and launch as soon as the treatment looks positive. How would you handle interim reads without inflating false positives?"
Turn 3: The Two-Sided Marketplace
Interviewer: "How would you deal with the fact that users and creators interact through a shared marketplace, so treatment on one side may affect outcomes for others?"
Turn 4: The Mixed-Results Decision
Interviewer: "If early results show improved clicks and watch time but worse creator diversity and weaker next-week retention, how would you structure the launch decision?"
Why Reading This Isn't Enough
Spotting Devon's mistakes on the page is easy; the guardrail should have been a hard stop, the peeking control was missing, the creators never got mentioned. None of that is hard to see with the answer already in front of you and no clock running. Catching it live, mid-sentence, while the interviewer is already asking the next follow-up, is the actual skill being scored. That gap only closes with reps, which is exactly what a live AI mock interview is for: the same scenario, the same follow-ups, real time pressure, and a scored transcript afterward instead of a blog post telling you what you should have said.
The Complete Blueprint
Here is the full 30-minute structure a strong candidate hits, phase by phase. This is the exact thing the AI interviewer tracks you against while you talk, not a checklist you read afterward.
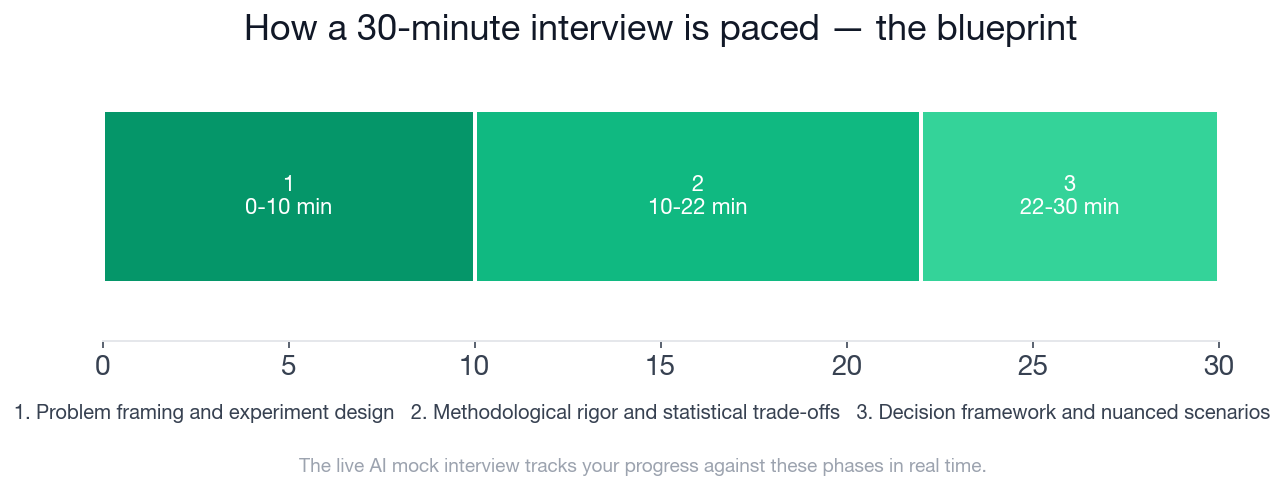 Phase 3 packs its five checklist items into the tightest window of the three phases, just 8 minutes to structure a decision on mixed results.
Phase 3 packs its five checklist items into the tightest window of the three phases, just 8 minutes to structure a decision on mixed results.
- ✓Clarifies what decision the experiment is meant to support: full launch, limited rollout, or no launch
- ✓Defines user-level randomization and notes exposure should be tied to actually seeing the home feed
- ✓Names a primary metric aligned to the ranking change rather than listing many unrelated metrics
- ✓Introduces guardrails such as retention, session quality, creator diversity, content satisfaction, or ecosystem health
- ✓Mentions experiment population, ramp strategy, and basic duration considerations
- ✓Explains power versus MDE trade-off in practical terms and ties it to business value and experiment cost
- ✓Acknowledges risks from repeated peeking and proposes a valid approach such as fixed horizon reads, alpha spending, or pre-specified interim rules
- ✓Recognizes multiple comparison issues from many cuts or metrics and distinguishes confirmatory from exploratory analysis
- ✓Identifies at least two validity threats such as sample ratio mismatch, instrumentation bias, novelty effects, triggered analysis pitfalls, or contamination
- ✓Suggests a sensitivity improvement or variance reduction approach such as CUPED, covariate adjustment, stratification, or using pre-period behavior
- ✓Provides a concrete launch rule or decision rubric rather than saying 'it depends' without structure
- ✓Handles conflicting metrics by prioritizing pre-declared primary outcomes and non-negotiable guardrails
- ✓Notes that marketplace or network effects may require holdouts, cluster-based designs, creator-side monitoring, or phased rollout
- ✓Proposes a practical next step if results are mixed, such as follow-up experiment, longer holdback, reduced ramp, or segment-specific launch
- ✓Communicates trade-offs clearly and avoids overclaiming from short-term engagement gains alone
Practice This Interview
Reading Devon's mistakes builds pattern recognition; running the same 30-minute scenario live against the AI interviewer is what tests whether that recognition survives under pressure. Start the AI mock interview for a scored, phase-by-phase read on your own answer to this exact scenario. If you want to warm up on the underlying concepts first, drill statistical power, peeking, and validity threats individually in the experimentation methodology question bank, or browse the broader Research Scientist preparation guides for company-specific process notes.
FAQ
Q. What does a Research Scientist experimentation interview at the mid-level actually test?
A 30-minute, 3-phase simulation: problem framing and experiment design (0-10 min), methodological rigor and statistical trade-offs (10-22 min), and a decision framework for ambiguous results (22-30 min). Four rubric dimensions score it: Interviewer Objectives Alignment (30 points), Level-Specific Expectations (30 points), Technical Proficiency (20 points), and Communication & Problem Solving (20 points).
Q. What's the single biggest mistake candidates make in this interview?
Treating the scenario as a pure engagement-optimization problem. The prompt explicitly flags that the ranking change could affect creator ecosystem outcomes, so a primary metric with no non-negotiable guardrail concedes points on both Interviewer Objectives Alignment and Level-Specific Expectations before the statistics questions even start.
Q. How do you handle interim results without inflating false positives?
Name the risk directly: repeated peeking gives each daily look a fresh chance to cross a significance threshold by noise alone. Propose one concrete control, a fixed horizon read, a sequential method with alpha spending, or pre-specified interim decision rules, rather than agreeing to "check daily and launch when it looks good."
Q. Do you need to derive statistical formulas in this interview?
No. The level-specific bar for a mid-level Research Scientist is making pragmatic decisions with reasonable assumptions, not deriving power calculations from scratch. What is expected is recognizing the trade-offs (power versus minimum detectable effect, sequential testing risk, multiple comparisons) and proposing a workable approach.
Q. How should you structure a launch decision when results are mixed?
Go back to the decision rule you declared during framing. If the primary metric improved but a pre-declared guardrail was breached, the rule says no full launch, and the next step is a phased rollout, a follow-up experiment targeting the regression, or a segment-specific launch, not an open-ended "it depends."
Q. Is this based on a real company's actual interview questions?
No. The scenario is illustrative of how a rigorous experimentation interview for this role and level runs; it does not reproduce any specific employer's real question set.
Q. How can I practice this exact interview?
Start a live AI mock interview built on this same blueprint. It tracks you against the same phases and checklist items in real time and gives you scored feedback at the end, the closest thing to a rep before the real interview.
The Decision Rule Is the Deliverable
The statistics in this interview are table stakes; most mid-level candidates can name CUPED or explain why peeking is dangerous if asked directly. What separates a strong answer is whether the guardrail declared in minute three survives to the decision in minute twenty-eight, unchanged, still blocking the launch it was meant to block. That consistency is what the blueprint above is actually measuring, and it is far easier to plan on paper than to hold under a live follow-up you did not expect.
Topics
Ready to practice?
Put what you've learned into practice with AI mock interviews and structured preparation guides.