The Research Scientist Title Is Hiding a Fork in the Road
Put "Research Scientist" into any job search and two very different roles come back. One is a foundational AI researcher: training LLMs, designing RL algorithms, pushing the frontier of what models can do. The other is a product research scientist: running A/B tests on recommendations, measuring lift on ranking systems, building the experiments that decide what ships. Both carry the same title. Both require the same two table-stakes skills (Machine Learning and Python). Beyond that, the skill stacks diverge sharply, and so does the kind of career that follows.
Across 1,065 active Research Scientist postings on the InterviewStack.io job board, A/B Testing appears in 39.1% of listings and PyTorch appears in 37.9%. Those two numbers are essentially tied, despite describing almost opposite research philosophies. One measures the empirical scientist who validates hypotheses on live product traffic; the other measures the model builder who trains and evaluates in the lab. The fact that they co-exist at the same frequency is the clearest signal in the data: the market is buying both tracks in equal measure.
The salary data adds the implication. The skills that push Research Scientist compensation farthest above the $193,800 US median are not additional ML depth. They are scale and infrastructure: running distributed training across hundreds of GPUs, building data pipelines for model training at scale, managing Kubernetes clusters for research workloads. Researchers who can close the gap between an experimental notebook and a trained model in production earn $26K to $44K above baseline. Knowing more theory, by contrast, barely moves the number.
Key Findings
- 1,065 distinct Research Scientist postings analyzed from the InterviewStack.io job board, June 2026.
- Only two table-stakes skills: Machine Learning (61.8%) and Python (57.6%).
- A/B Testing (39.1%) and PyTorch (37.9%) are statistically tied as the third and fourth most-demanded skills, revealing the product vs. foundational research split.
- Median US base salary is $193,800 across 400 postings with US salary disclosed (equity and bonuses not included).
- Infrastructure skills command the largest premiums: Distributed Training ($238,000, +$44,200), Data Pipelines ($231,800, +$38,000), and Kubernetes ($220,000, +$26,200).
- LLM specialization adds $20-22K: LLMs ($213,800) and Model Training ($215,000) form a clear second tier above baseline.
- Entry-level is only 5.1% of openings (55 of 1,065); 65% of postings target mid-level candidates.
- 63% of postings are onsite, one of the highest rates for any research role, reflecting GPU clusters, robotics labs, and specialized compute requirements.
Dataset scope: The 'Research Scientist' title spans a wide range of scientific disciplines in job postings. The majority of this dataset consists of tech and AI Research Scientists at software companies, AI labs, and research-intensive technology organizations. A portion of adjacent roles (quantitative researchers in finance, operations research scientists, computational biologists, and some clinical research positions) also carry the same title and appear in the dataset. The ML and AI skill frequencies that dominate the top 10 skills, and the salary medians above $190K, reflect the tech and AI-lab majority. Readers targeting highly specialized sub-disciplines (biotech RS, clinical RS, industrial OR) may see different skill frequencies in their segment.
Salary Structure Has Three Counterintuitive Tiers
All figures below are US-only base salaries from postings with wage-transparency disclosures, so they are directly comparable. Equity, RSUs, bonuses, and sign-on are not captured in posting data; at AI labs like OpenAI and Anthropic, total compensation runs meaningfully higher than what we report here. The US base median across 400 postings is $193,800.
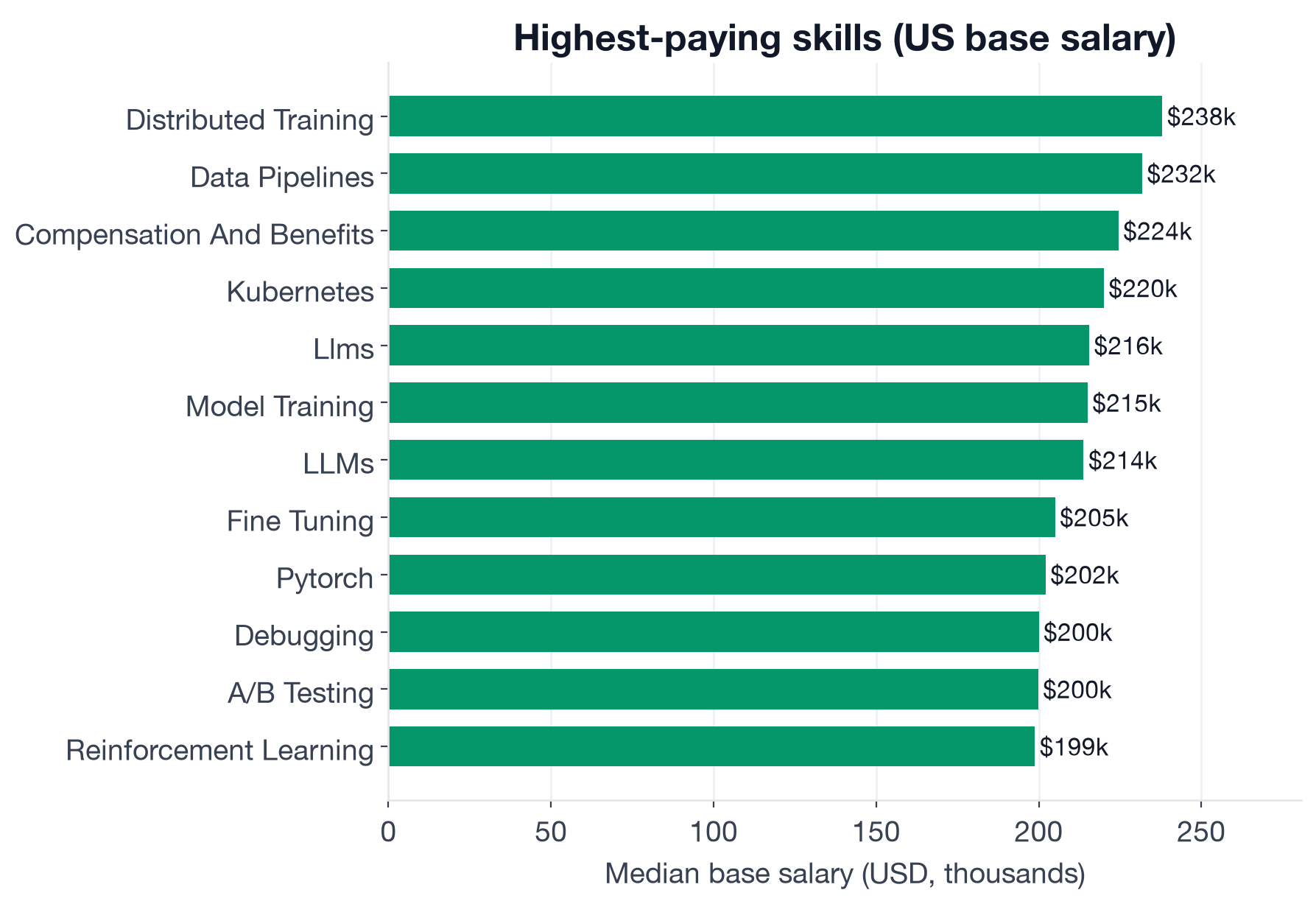
Median US base salary for Research Scientist postings that mention each skill. Restricted to US postings with structured salary data; skills with fewer than 25 US data points excluded.
The premium structure has three tiers, and the order is counterintuitive.
Tier 1: Scale and infrastructure. The largest premiums belong to skills that move research from notebook to cluster:
| Skill | US Median | Premium over $193,800 baseline |
|---|---|---|
| Distributed Training | $238,000 | +$44,200 |
| Data Pipelines | $231,800 | +$38,000 |
| Kubernetes | $220,000 | +$26,200 |
These are not pure ML research skills. They are operational ones: running multi-GPU training jobs efficiently, keeping model data pipelines reliable, managing container orchestration for research workloads. The fact that they command the largest premiums in a "Research Scientist" salary table reflects a market reality: companies pay most for researchers who can own the full lifecycle, not just the experiment design.
Tier 2: LLM specialization. Depth in language models adds $20K to the baseline:
| Skill | US Median | Premium |
|---|---|---|
| LLMs | $213,800 | +$20,000 |
| Model Training | $215,000 | +$21,200 |
| Fine Tuning | $205,000 | +$11,200 |
Tier 3: Core ML skills near baseline. The table-stakes skills confirm they have hit commodity status:
| Skill | US Median | vs. baseline |
|---|---|---|
| PyTorch | $202,100 | +$8,300 |
| A/B Testing | $199,800 | +$6,000 |
| Reinforcement Learning | $198,800 | +$5,000 |
| Machine Learning | $194,200 | +$400 |
| Python | $193,200 | -$600 |
Machine Learning and Python appear in 62% and 58% of postings respectively. At that frequency, they stop differentiating candidates: everyone has them, so the market stops paying extra for them. Deep Learning ($193,000), Algorithms ($193,800), and Computer Vision ($191,800) follow the same pattern: important for getting the job, insufficient for moving the offer.
Two below-baseline results are worth flagging. C++ shows a US median of $184,000 (-$9,800), which likely reflects the robotics and hardware-adjacent Research Scientist segment where compensation structures differ from software AI labs. More striking: postings that use "data science" as a primary skill keyword show a US median of $164,700, a full $29,100 below baseline. That label tags a lower tier of the Research Scientist market, closer to applied analytics than to frontier model work.
What Skill Families Shape the Role?
Group every individual skill into its broader family and count the share of postings that ask for at least one skill from each group.
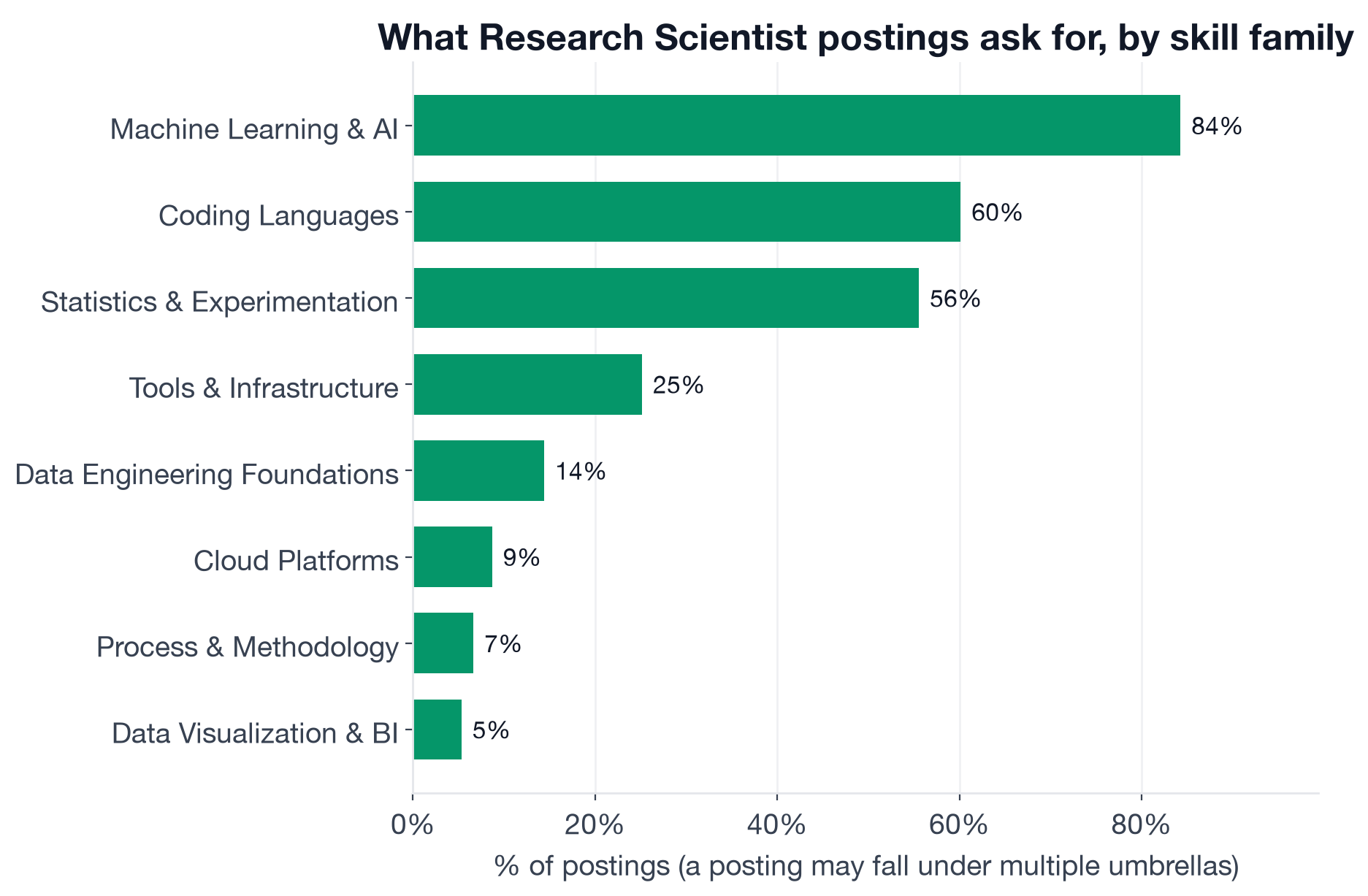
Share of Research Scientist postings that ask for at least one skill in each family. A posting that mentions both PyTorch and TensorFlow counts once under Machine Learning & AI.
The "Other" umbrella (Algorithms, the LLM skill cluster, Reinforcement Learning, Fine Tuning, Model Training, RLHF, Distributed Training) reaches 90.7% of postings. Machine Learning & AI covers 84.3%. Together, these two families confirm that deep algorithmic and model expertise is the baseline, not the differentiator: practically every Research Scientist posting asks for it, so it gets the role but not the premium.
Statistics & Experimentation at 55.6% is the second most revealing figure. Driven almost entirely by A/B Testing (39.1%) and Statistics (24.1%), it confirms that product-track research skills are present in the majority of postings, not a niche. More than half of postings explicitly want experimental design capability alongside model skills.
The infrastructure families are small by volume but salary-weighted. Tools & Infrastructure covers only 25.2% and Cloud Platforms covers just 8.7%, yet these are the exact families that command the top salary premiums in the table above. Selective demand, high reward.
The Fork Shows Up Clearly in the 20-50% Tier
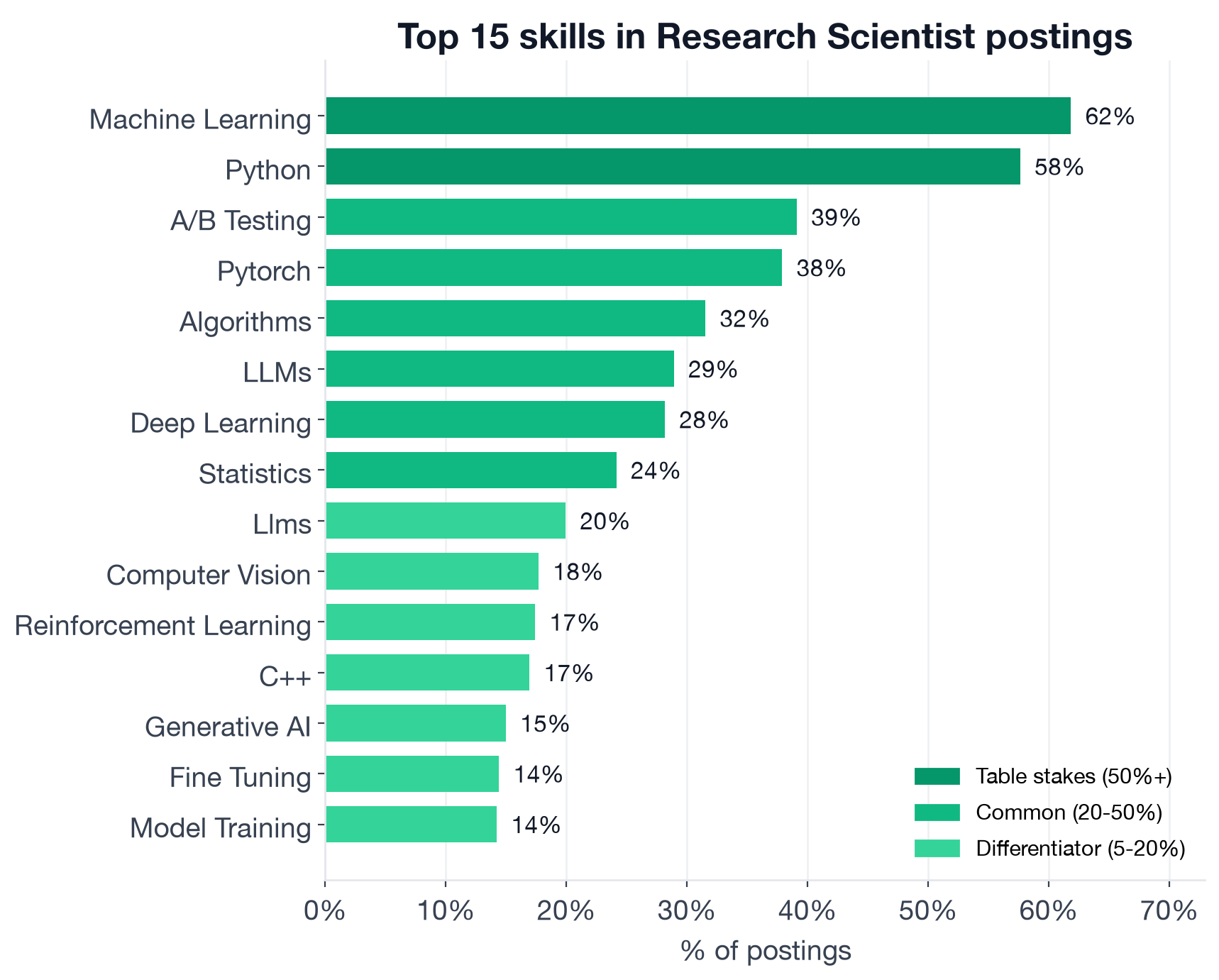
Top individual Research Scientist skills by share of listings. Skills above 50% are table stakes; 20-50% are common; 5-20% are differentiators.
Table Stakes (50%+ of postings)
Two skills and only two clear the 50% line:
- Machine Learning: 61.8% (browse Research Scientist openings that ask for ML)
- Python: 57.6% (Research Scientist + Python openings)
This is the narrowest table-stakes tier of any role in our dataset. Where a Data Engineer posting has three near-universal requirements and a Business Intelligence Analyst has a dense cluster of SQL and BI tools, a Research Scientist posting has two. Everything else is a configuration choice that depends on the employer's research focus. If your resume cannot clearly demonstrate both ML depth and Python, you are filtered before a recruiter reads a line.
Common Expectations (20-50% of postings)
This is where the product vs. foundational research split becomes legible in the numbers:
- A/B Testing: 39.1% (experimentation infrastructure, live product validation)
- PyTorch: 37.9% (Research Scientist + PyTorch openings)
- Algorithms: 31.5% (theoretical depth, especially at AI labs)
- LLMs: 28.9%
- Deep Learning: 28.2%
- Statistics: 24.1%
The parallel positioning of A/B Testing and PyTorch is the finding this post is built on. A posting that lists A/B Testing and a posting that lists PyTorch are describing very different research workflows. One is running experiments on product traffic and measuring causal effects; the other is training neural networks and evaluating model behavior. The market needs both at roughly equal scale, which means picking a track is a real career decision, not just a resume choice.
Differentiators (5-20% of postings)
- Computer Vision: 17.7% (autonomous systems, medical imaging, perception research)
- Reinforcement Learning: 17.4% (RL-focused Research Scientist openings)
- C++: 16.9% (performance-critical ML, robotics, embedded research)
- Generative AI: 15.0%
- Fine Tuning: 14.4%
- Model Training: 14.2%
- TensorFlow: 13.6%
- Large Language Models: 12.5%
- JAX: 12.4%
- Data Pipelines: 9.4%
- NLP: 8.9%
- Distributed Training: 8.4%
- RLHF (Reinforcement Learning from Human Feedback, the alignment technique behind instruction-tuned LLMs): 5.9%
- Kubernetes: 5.4%
Two entries in this tier deserve a closer look.
C++ at 16.9% differentiator demand is high for a research role. In most data and analytics roles, C++ is barely present. In Research Scientist postings, it marks the systems-performance track: robotics, real-time ML inference, hardware-adjacent research, and any context where Python's runtime overhead is too expensive for the experimental loop. The salary data, however, shows C++ postings ($184,000) at $9,800 below the role baseline, which suggests this track is concentrated in companies (defense-tech, robotics, hardware) where research compensation runs differently from pure software AI labs.
JAX (a numerical computation library from Google that compiles XLA kernels, enabling fast gradient computation across TPUs and GPUs) at 12.4% appears almost exclusively alongside PyTorch (co-occurrence lift of 2.52, the third-highest pair in the dataset). That lift signals the multi-framework AI lab environment: researchers at Google-adjacent labs and frontier model teams work across both frameworks depending on the training target.
On ambient AI tool use: the 84.3% ML & AI umbrella and the individual skill frequencies above capture Research Scientists hired to build and advance AI systems: they measure the "Build AI" layer. But a second layer runs beneath every posting. Developer surveys show 85% of professionals regularly use AI tools (JetBrains State of Developer Ecosystem 2025) and 51% use them daily (Stack Overflow Developer Survey 2025). For Research Scientists specifically, that ambient layer is even denser: they write PyTorch and JAX code that Copilot assists directly, they use AI tools for literature review and hypothesis generation, and GitHub's Octoverse reports rapid, widespread adoption of Copilot among new users on the platform. No Research Scientist posting in 2026 says "uses ChatGPT for literature review" as a required skill, yet that expectation is effectively universal. The explicit AI percentages measure who is building AI systems. The ambient layer is the productivity baseline they operate on top of.
How Do Research Scientist Skills Actually Stack Together?
The co-occurrence table shows which skill pairs appear together more often than individual frequencies alone would predict:
| Skill pair | Postings mentioning both | Share of postings | Lift |
|---|---|---|---|
| PyTorch + TensorFlow | 142 | 13.3% | 2.58 |
| JAX + PyTorch | 127 | 11.9% | 2.52 |
| Deep Learning + PyTorch | 200 | 18.7% | 1.75 |
| C++ + Python | 170 | 15.9% | 1.63 |
| Computer Vision + Machine Learning | 160 | 15.0% | 1.37 |
| Python + PyTorch | 306 | 28.6% | 1.31 |
| Machine Learning + Statistics | 208 | 19.5% | 1.30 |
| A/B Testing + LLMs | 150 | 14.0% | 1.24 |
| Machine Learning + Python | 429 | 40.1% | 1.13 |
Lift > 1 means the pair appears together more often than their individual frequencies predict. Source: top-25 skill co-occurrence analysis across 1,065 postings.
PyTorch + TensorFlow (lift 2.58) and JAX + PyTorch (lift 2.52) are the highest-lift framework combinations in the dataset. Multi-framework fluency is not the norm for most ML engineers, but Research Scientists at frontier labs routinely work across both: JAX for XLA-accelerated training on TPUs, PyTorch for research flexibility, TensorFlow for production serving. These pairs tag postings at NVIDIA, DeepMind, and Google-adjacent labs where the full training stack is heterogeneous by design.
Deep Learning + PyTorch (lift 1.75) is the core foundational researcher signal: postings that ask for deep learning research almost always mean PyTorch. The lift of 1.75 means this pair co-occurs 75% more often than independence would predict, making it the tightest functional coupling in the data.
C++ + Python (lift 1.63) marks the systems-performance track. These postings want a researcher who prototypes in Python and then drops into C++ for the inference or deployment path. Think robotics, real-time computer vision, and any embedded research context. Research Scientist openings with both C++ and Python are a distinct hiring segment from the pure-software AI stack.
Machine Learning + Statistics (lift 1.30) is quieter but important. It tags the experimental-rigor track: postings that ask for both are typically product research scientist roles where you're running experiments that have to be statistically defensible, not just ML models that have to be accurate.
A/B Testing + LLMs (lift 1.24) is the product research scientist fingerprint in the LLM era. A posting that asks for both is evaluating language model features on live traffic, measuring their causal effect, and designing the experiment pipeline that gates what ships. Browse postings that combine A/B Testing and LLMs.
How Selective Is the Seniority Distribution?
The entry-level picture for Research Scientist is one of the tightest in tech hiring.
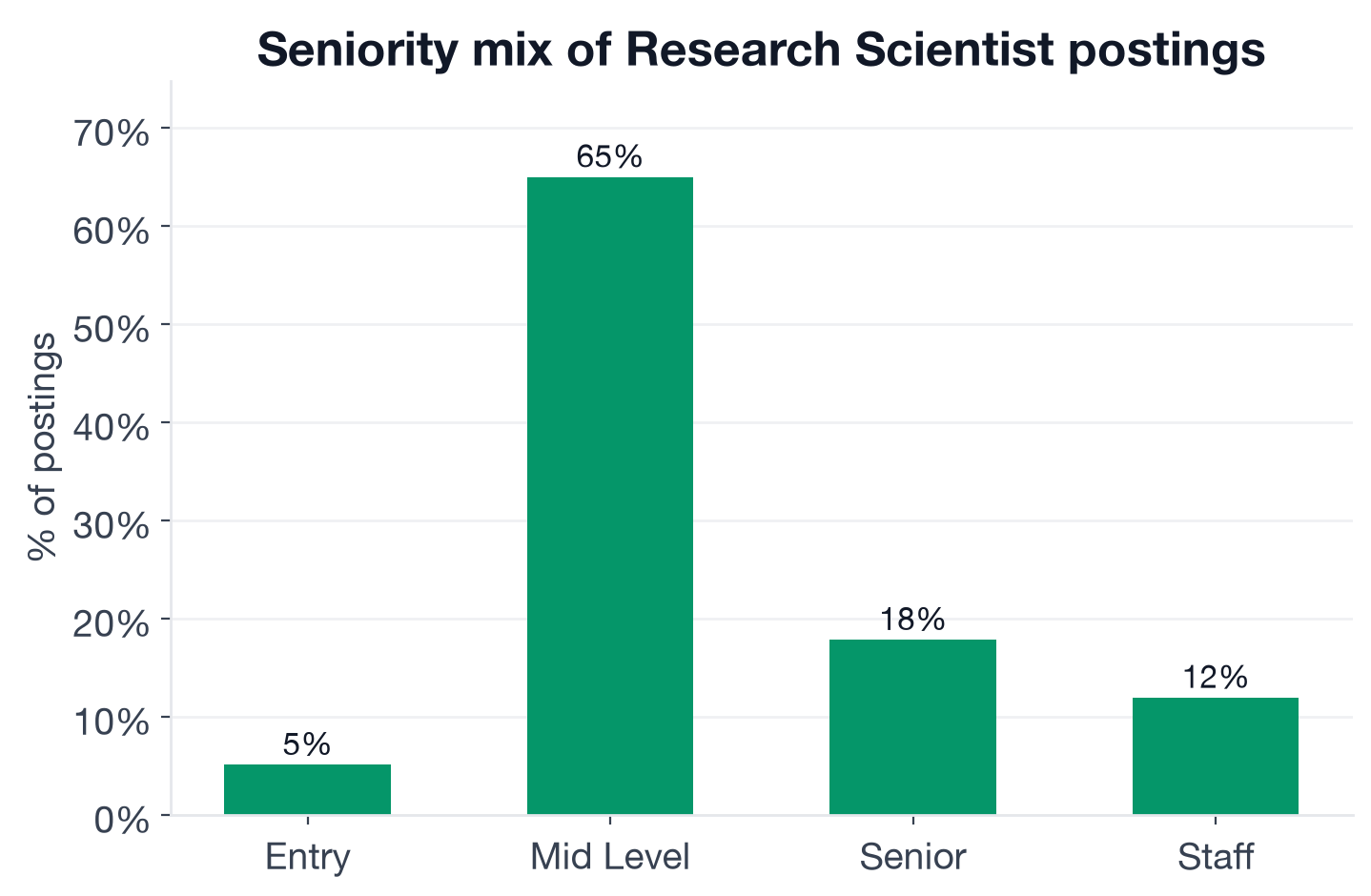
Seniority distribution of Research Scientist postings, inferred from title keywords.
- Mid-level: 65.0% (695 postings)
- Senior: 17.9% (191) (senior Research Scientist openings)
- Staff: 12.0% (128)
- Entry: 5.1% (55)
Only 1 in 20 postings is entry-level. But the more revealing number is the 65% mid-level share, one of the highest mid-level concentrations of any role we have analyzed. Research Scientist is not a career ladder you climb into: companies expect you to arrive mid-level already. For the majority of postings, that means a PhD or 3 to 5 years of applied ML research with demonstrable output, whether that is publications, shipped model features, or sustained experimental programs.
The entry 5.1% (55 postings) is not a slow-ramp path for career changers. It is mostly formal intern and graduate research programs at labs with structured recruiting cycles (NVIDIA, Anthropic, OpenAI). For people transitioning from ML engineering or data science, the more realistic path is targeting mid-level postings where applied research experience in a product context is the explicit credential, not a PhD dissertation.
The staff tier at 12% (128 postings) is real. Staff Research Scientists own research agendas, not just projects: they define what the team investigates, mentor junior researchers, and make the architectural decisions that determine what the lab bets on for the next 12 months. Postings at this level surface the infrastructure-premium skills most clearly: distributed training, large-scale model training programs, and system-scale experimental design appear most prominently at this tier.
Where Are the Jobs, and How Is the Work Structured?
Research Scientist is more US-concentrated and more onsite-heavy than almost any other research or data role.
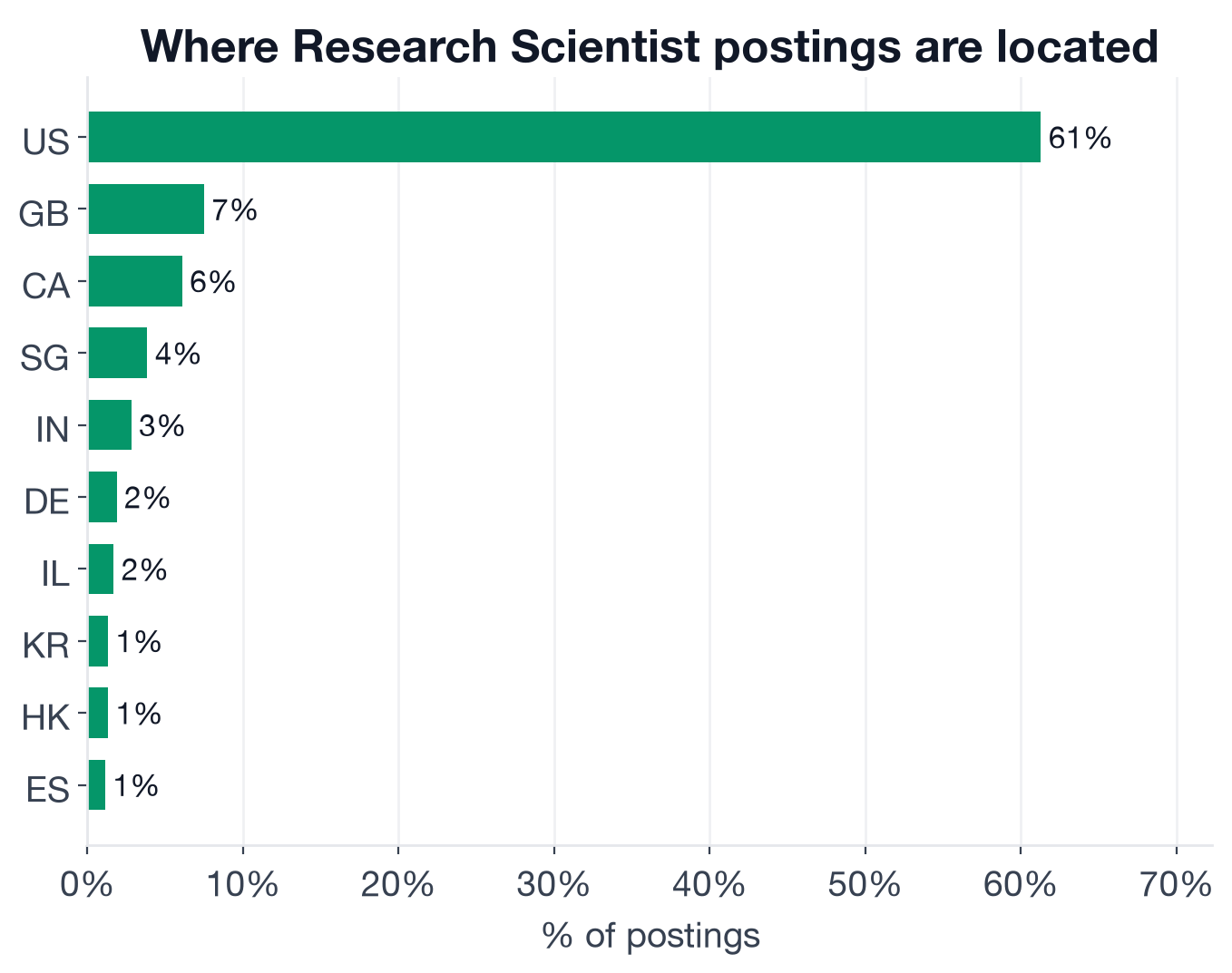
Top countries by share of Research Scientist postings.
- United States: 61.2% (US Research Scientist openings)
- United Kingdom: 7.5% (London AI lab concentration: DeepMind, Wayve, and the UK's sovereign AI investment)
- Canada: 6.1% (Toronto-Waterloo corridor, Huawei Canada AI lab, Vector Institute affiliates)
- Singapore: 3.8% (Nanyang Technological University, regional AI investment)
- India: 2.8%
- Germany: 1.9%
Three English-speaking markets (US, UK, Canada) account for nearly 75% of all postings. That is more geographically concentrated than Software Engineer hiring, more concentrated than ML Engineer hiring, and it compounds with the onsite rate below to make physical location a genuine constraint.
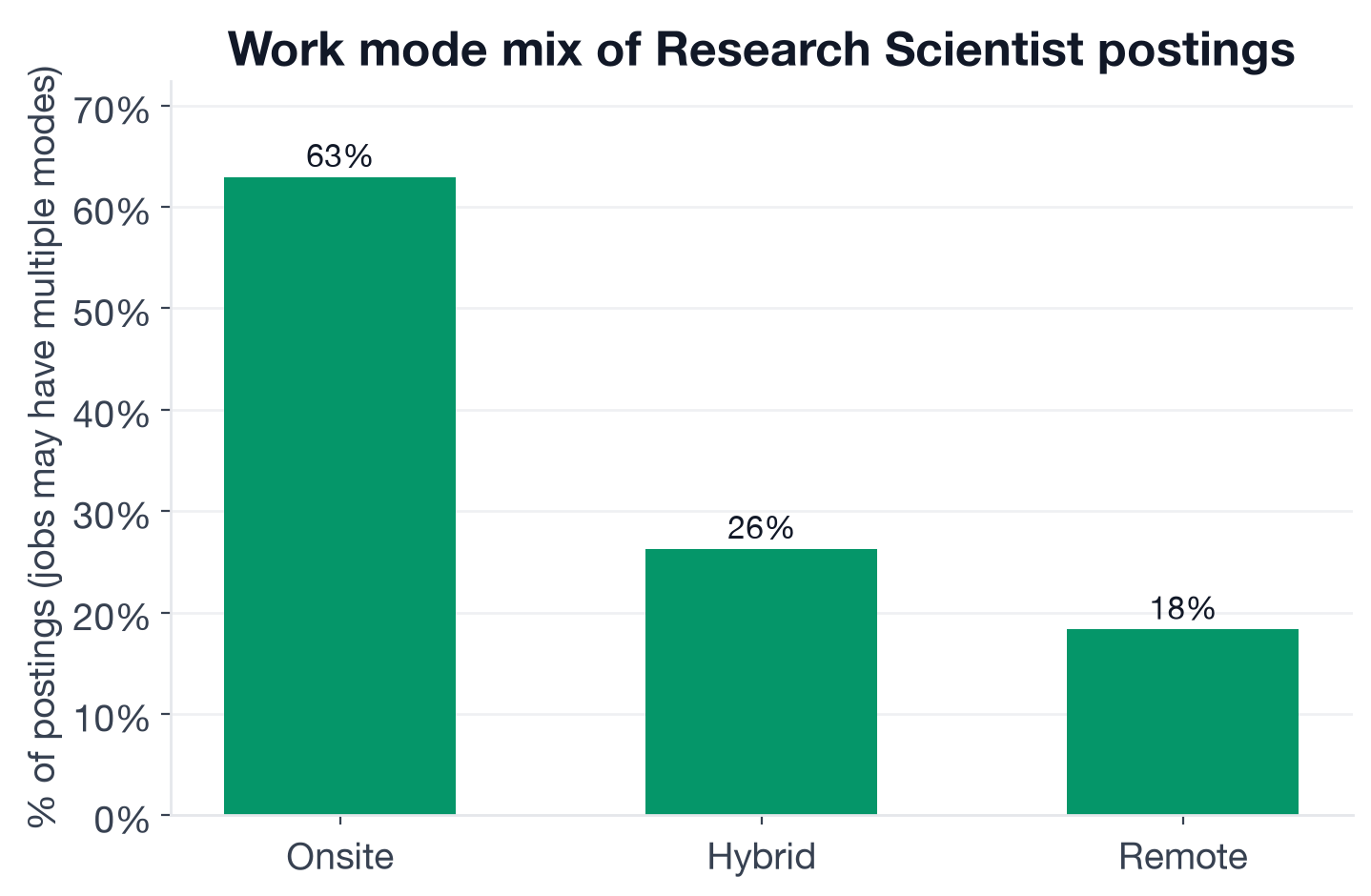
Work mode distribution for Research Scientist postings.
- Onsite: 63.0% (673 postings)
- Hybrid: 26.3% (281)
- Remote: 18.3% (196) (remote Research Scientist openings)
Work-mode tags are not mutually exclusive; a posting may carry both hybrid and onsite flags, so these percentages sum above 100%.
The 63% onsite rate is unusually high for a role whose deliverables are largely code and papers. The explanation is infrastructure access: GPU clusters, custom silicon, robotics hardware, and specialized compute environments that researchers need physical proximity to. Labs like NVIDIA, Boston Dynamics, and Anduril have inherently onsite research cultures. Even the software-first AI labs (OpenAI, Anthropic) run hybrid-first rather than fully remote for research roles, because the collaboration pattern that produces research breakthroughs is heavily in-person.
Remote Research Scientist roles do exist at 18.3%, concentrated in companies with distributed research programs and mature remote-work infrastructure. But if full remote is a requirement for you, this title offers a narrower pool than most data and engineering roles.
Who's Hiring Research Scientists in 2026?
The employer roster for Research Scientist is one of the cleanest on the board: AI labs, chip designers, defense-tech, and specialized R&D organizations, with no significant staffing-firm or reposting artifacts.
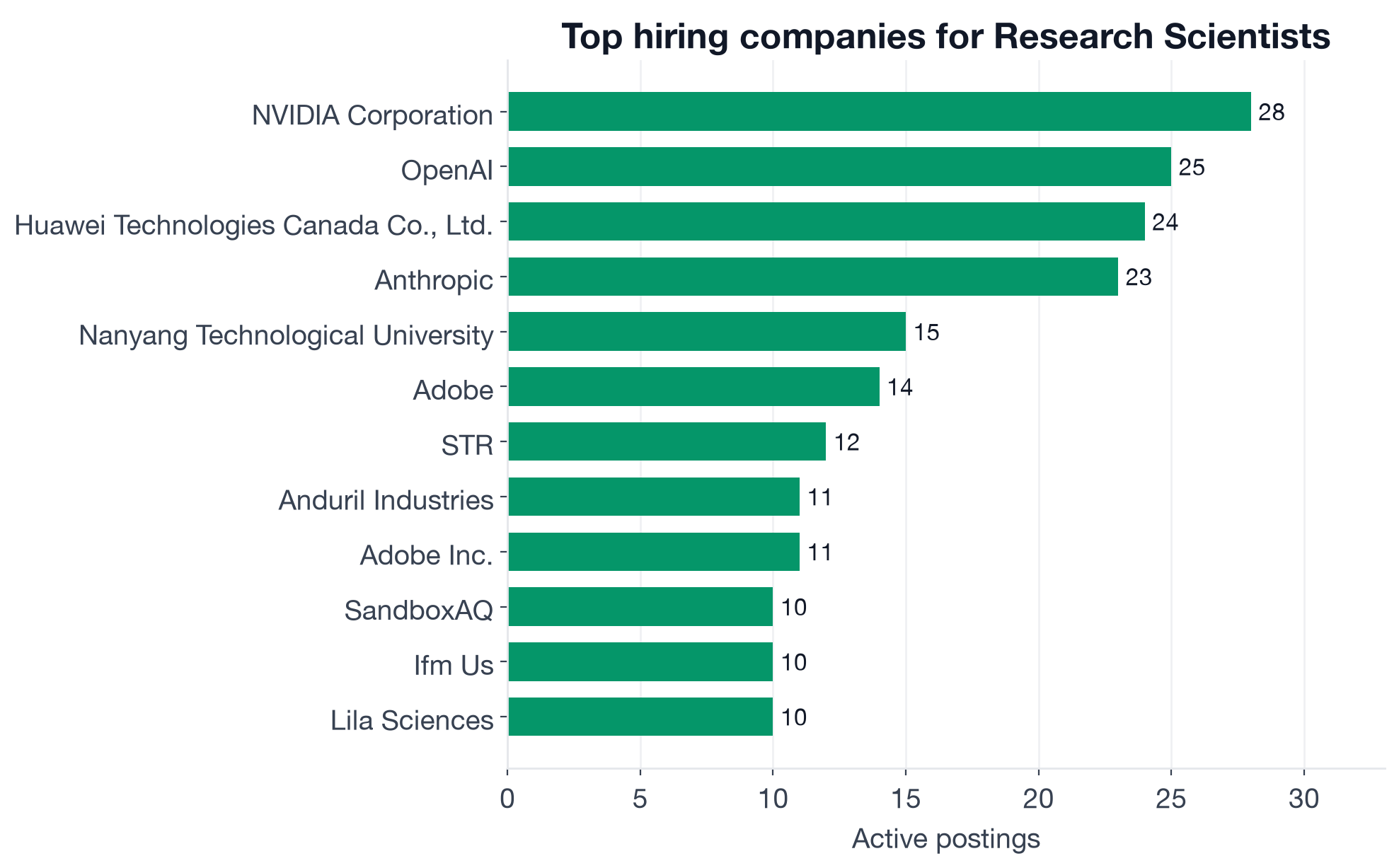
Top employers by distinct Research Scientist postings on the InterviewStack.io job board.
| Employer | Postings | Research focus |
|---|---|---|
| NVIDIA | 28 | GPU architecture, performance ML, CUDA systems |
| OpenAI | 25 | Frontier model research, RLHF, alignment |
| Adobe | 25 (two entity names) | Creative AI, generative models, computer vision |
| Huawei Canada | 24 | AI systems, language models, hardware-software co-design |
| Anthropic | 23 | Safety research, constitutional AI, alignment |
| Nanyang Tech. University | 15 | Academic AI research, SE Asia hub |
| Anduril Industries | 11 | Defense perception, autonomy, computer vision |
| SandboxAQ | 10 | Quantum ML, post-quantum security research |
| Lila Sciences | 10 | AI for drug discovery and molecular biology |
| DeepMind | 10 | Foundational AI, RL, scientific applications |
| Boston Dynamics | 9 | Robotics locomotion, real-world ML, perception |
| Autodesk | 9 | Generative design, CAD/BIM AI, geometry ML |
| Jane Street | 8 | Quantitative research, ML for markets |
| Dolby | 8 | Audio ML, perceptual models |
The range tells you something important about what the title actually covers. At NVIDIA or Boston Dynamics, Research Scientist means performance-critical ML close to hardware; the C++ differentiator and the systems skills matter here. At OpenAI or Anthropic, it means frontier model research and alignment; RLHF, Fine Tuning, and LLM depth are central. At Lila Sciences or SandboxAQ, it is domain-specific AI with niche compute and experiment requirements. Each of these companies recruits differently and tests differently. For company-specific interview preparation, the InterviewStack.io preparation guides break down what each hiring process actually looks for by round.
How to Use This in Your Job Search
Decide which track you are on before you apply. The A/B Testing vs. PyTorch parity in the data is not a coincidence: it reflects two genuinely different Research Scientist markets. Product research scientists need to demonstrate experimental rigor, from randomization and power analysis through to causal inference and decision-making under uncertainty. Foundational AI researchers need to demonstrate model architecture judgment, research output, and the ability to push capability beyond current benchmarks. Trying to present as both without a genuine background in both is usually detectable in a screening round.
Target the infrastructure premium deliberately. If you are aiming for the $220K-$238K tier, the path runs through distributed training experience, ML data pipeline engineering, and container orchestration. These are not traditional pure-research skills, but the salary table is clear: they command the largest premiums in this title. Browse Research Scientist postings that emphasize distributed training. The question bank covers algorithmic problem-solving and statistics topics that come up in Research Scientist screening rounds; drill those topics before your first phone screen.
Match your framework depth to your target employer. The co-occurrence data shows PyTorch + TensorFlow (lift 2.58) and JAX + PyTorch (lift 2.52) appearing together almost exclusively in multi-framework lab environments. At the mid-level, depth in one framework stack matters more than nominal familiarity with three. Pick PyTorch as the default for NLP and vision research; pick JAX if you are targeting Google-adjacent or TPU-centric labs; add TensorFlow only if your target employer explicitly lists it. Our interactive courses cover the ML and statistics foundations relevant to both the product and foundational tracks.
Practice the research conversation, not just the coding screen. Research Scientist interviews are heavier on paper-reading discussion, experiment design critique, and "how would you design this study" rounds than standard ML engineering loops. AI mock interviews let you rehearse under realistic conditions and get feedback on research design questions specifically. Use the job board filter to identify which companies are hiring now and refine by skill to surface postings that match your strongest specialization.
FAQ
Q. What skills do companies require from Research Scientists in 2026?
Machine Learning (61.8% of postings) and Python (57.6%) are the only table-stakes skills. Above that, A/B Testing (39.1%), PyTorch (37.9%), Algorithms (31.5%), LLMs (28.9%), Deep Learning (28.2%), and Statistics (24.1%) sit in the common tier. Differentiators include Computer Vision, Reinforcement Learning, C++, Generative AI, Fine Tuning, Model Training, and JAX (all between 5% and 20% of postings).
Q. What is the median Research Scientist salary in 2026?
The median US base salary is $193,800 across 400 Research Scientist postings with disclosed US salary data. Equity and bonuses are not captured in posting data, so total compensation at AI labs and top tech employers is meaningfully higher than these figures.
Q. Which Research Scientist skills command the largest salary premiums?
Among US postings, infrastructure and scale skills carry the largest premiums over the $193,800 baseline: Distributed Training ($238,000, +$44,200), Data Pipelines ($231,800, +$38,000), and Kubernetes ($220,000, +$26,200). LLM specialization adds $20-22K: LLMs ($213,800) and Model Training ($215,000) both sit in that range. By contrast, Machine Learning itself ($194,200) and Python ($193,200) are at baseline, because they appear in nearly every posting and no longer differentiate.
Q. Is Research Scientist an entry-level role to break into?
Rarely. Only 5.1% of Research Scientist postings are explicitly entry-level (55 of 1,065), while 65% are mid-level and 18% senior. The mid-level majority reflects that companies expect candidates to arrive with research depth already established, typically from a PhD or equivalent research experience. Research Scientist postings at this level almost universally assume demonstrated publication or applied research output.
Q. How remote-friendly are Research Scientist jobs in 2026?
Research Scientist is one of the less remote-friendly roles in tech. Only 18.3% of postings are tagged remote; 63% are onsite and 26.3% hybrid. Labs working with GPU clusters, robotics hardware, or specialized compute require physical access. The 61.2% US concentration compounds this: most roles are physically located in US AI hubs.
Q. Which companies are the biggest Research Scientist employers in 2026?
The top employers on the InterviewStack.io job board are AI labs and tech hardware leaders: NVIDIA (28 postings), OpenAI (25), Adobe (25, appearing under two entity names), Huawei Canada (24), Anthropic (23), Nanyang Technological University (15), Anduril Industries (11), SandboxAQ (10), Lila Sciences (10), DeepMind (10), Boston Dynamics (9), Autodesk (9), Jane Street (8), and Dolby (8).
Q. What Research Scientist skill stack is most in demand right now?
The core co-occurrence stack is Python plus Machine Learning (40.1% of postings, lift 1.13) layered with PyTorch (Python + PyTorch at 28.6%, lift 1.31). JAX plus PyTorch (lift 2.52) and PyTorch plus TensorFlow (lift 2.58) mark the AI lab environment where multiple frameworks co-exist. A/B Testing plus LLMs (lift 1.24) signals the product research scientist stack, where experimentation and LLM deployment intersect.
Where to Focus Your 2026 Prep
Research Scientist sits at the intersection of high bar and high ceiling: $193,800 US base median, with $238K reachable for researchers who combine ML depth with distributed training experience. The fork between product-track and foundational-track is genuine, and the companies doing the most hiring (NVIDIA, OpenAI, Anthropic, Adobe, DeepMind) each represent a distinct slice of what this title actually requires day to day.
Explore active Research Scientist openings on the InterviewStack.io job board and use the skill filters to surface the postings that match your specific specialization, whether that is experimentation, model training, computer vision, or reinforcement learning.
Topics
Ready to practice?
Put what you've learned into practice with AI mock interviews and structured preparation guides.