A Solved Problem That Costs You the Offer
Here is what a mid-level software engineer data structures interview is really testing: not whether you know what a heap is. Whether you think before you code, compare approaches honestly, and hold your complexity reasoning together under follow-up pressure.
The rubric tells the story. Out of 100 points, 60 go to Interviewer Objectives Alignment (30 pts) and Level-Specific Expectations (30 pts) before a single line of code is evaluated. Technical Proficiency is worth 20 points. Communication and Problem Solving is another 20. A candidate who nails the implementation but jumps straight to coding without framing the trade-offs can sit at 45 points by the time they type their last return statement.
Jordan is a mid-level software engineer with four years of experience. The walkthrough below follows a 30-minute data structures and complexity interview at a leading tech company, drawn from a real blueprint used by the InterviewStack.io AI mock interview. Watch where Jordan's points go.
Key Takeaways
- 60 of 100 interview points go to problem framing and seniority-level reasoning, not code correctness.
- Jumping straight to implementation without stating assumptions and comparing approaches is the most common way mid-level candidates lose Interviewer Objectives Alignment points.
- "O(n log n)" is not a complete complexity answer: the rubric expects you to specify average vs. worst-case, amortized behavior where relevant, and total auxiliary space.
- Tie-breaking policy and edge cases for k equal to 0 and k greater than distinct queries are expected checklist items at this level.
- When record calls far outnumber getTopK calls, a hash map with on-demand sorting can outperform a maintained heap.
- Concurrency awareness (locking or snapshotting) is expected conceptually at mid-level; deep lock-free design is not.
- A 30-minute interview runs three phases: framing (0-7 min), implementation (7-22 min), complexity and edge cases (22-30 min).
What Problem Does the Interviewer Actually Set?
Jordan opens the call. The interviewer shares this problem context:
The interview question
You are building a backend component for a high-traffic consumer product. One endpoint needs to keep track of the most frequently used search queries in near real time so the product can display trending searches. Implement an in-memory data structure that supports these operations efficiently:
record(query: string) -> void getTopK(k: int) -> List[string]
Assume queries arrive one at a time, the same query may be recorded many times, and getTopK may be called repeatedly while updates are happening.
The interviewer follows: "Design and implement this data structure, and explain the time and space complexity of your approach and any trade-offs you are making."
Beneath that prompt sits a private checklist: can Jordan choose a data structure strategy that matches the operation mix, justify it with concrete complexity analysis, identify realistic edge cases, and communicate trade-offs rather than forcing a single answer? That checklist is what scores Jordan's session.
Turn by Turn: Where Jordan's Points Slip Away
Turn 1: The Opening Move
Interviewer: "Design and implement this data structure."
Turn 2: Workload Ratio
Interviewer: "If record is called far more often than getTopK, how does that change your design?"
Turn 3: Complexity Precision
Interviewer: "Compare a hash-map-plus-heap design with a bucket-based one on time and space."
Turn 4: Edge Cases
Interviewer: "What edge cases would you handle for ties, invalid k, and repeated getTopK calls?"
Why Spotting Mistakes on the Page Is Not Enough
Reading this walkthrough, you caught every error before Jordan made it. The gap is not pattern recognition; it is execution under live conditions, when the follow-up you did not anticipate lands 18 minutes in and you still have five minutes of edge-case discussion left on the clock.
That performance gap closes through reps. The only way to feel the difference between a confident approach-selection sequence and the instinct to start coding immediately is to run the interview for real: unscripted follow-ups, time pressure, feedback tied to the same four rubric dimensions described above. That only happens in a live session.
What Does a Strong Software Engineer Data Structures and Complexity Interview Look Like?
The blueprint below mirrors the live view the AI mock interview tracks you against in real time. Each phase has a time window and a concrete set of expected moves.
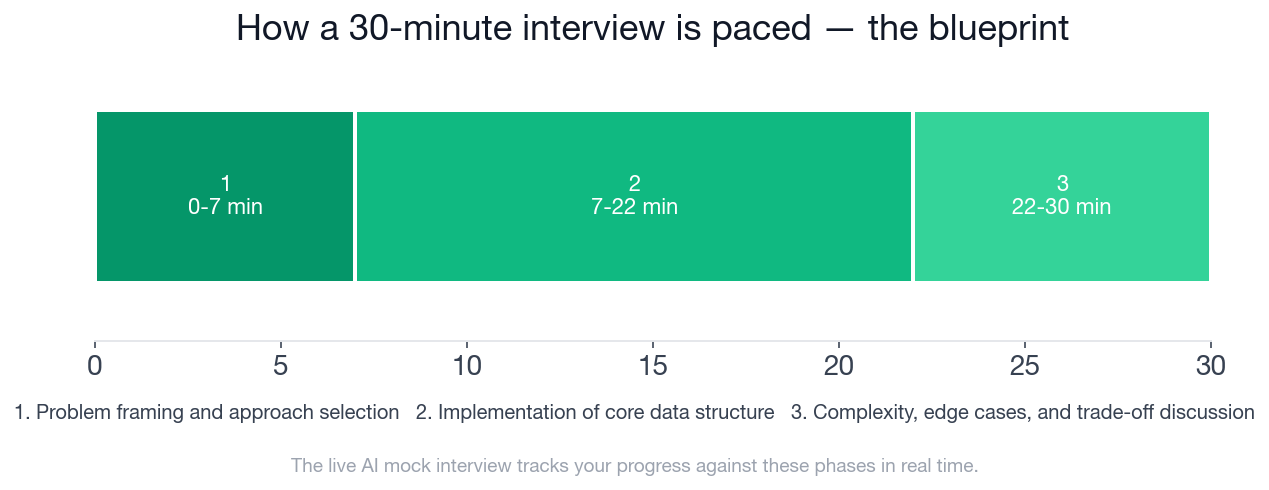
A strong candidate covers all three phases, spending the most clock time on implementation but earning the most points in framing and trade-off discussion.
- ✓Asks or states assumptions about tie-breaking, valid k range, and expected ratio of updates to reads
- ✓Identifies a baseline approach such as counting with a hash map and sorting on demand
- ✓Discusses at least one optimized alternative such as maintaining a heap, ordered buckets, or cached top-k results
- ✓Explains why the chosen approach fits the workload better than the baseline
- ✓Defines internal state clearly, such as a frequency map and supporting structure for ranking
- ✓Implements record correctly for both new and existing queries
- ✓Implements getTopK correctly with sensible handling for k less than 0, k equal to 0, or k larger than the number of distinct queries
- ✓Keeps code readable and consistent, with invariants or helper methods explained
- ✓Avoids obvious correctness issues such as stale heap entries without acknowledging them
- ✓States time complexity for both operations and total space complexity in terms of distinct queries and k
- ✓Explains whether complexity is average-case, worst-case, or amortized where relevant
- ✓Discusses tie handling and repeated getTopK calls without updates
- ✓Identifies bottlenecks for large distinct-query counts and proposes a reasonable improvement
- ✓Mentions at least a basic correctness approach for concurrent reads and writes, such as locking or snapshotting
The rubric scoring weights show how heavily framing and level judgment matter versus raw implementation speed.
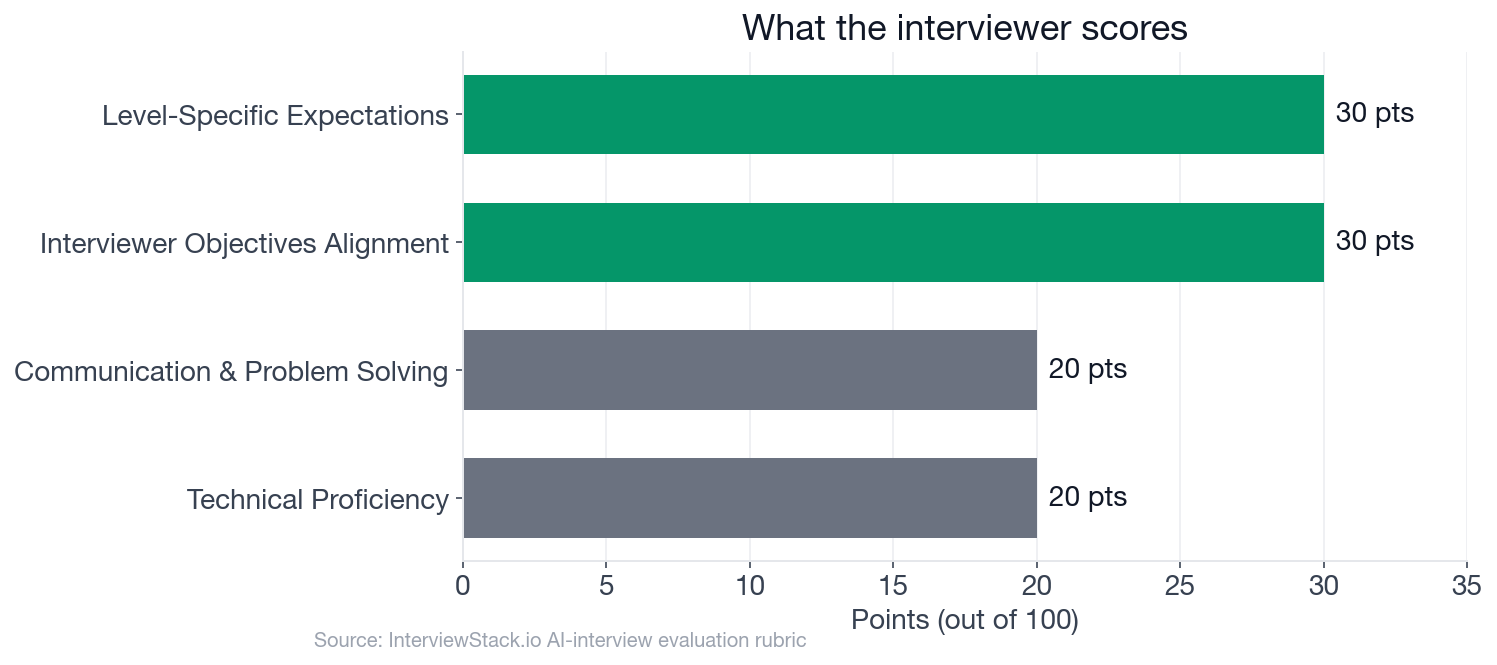
Technical Proficiency and Communication together account for 40% of the score. The remaining 60% goes to whether you framed the problem correctly and demonstrated mid-level judgment throughout.
Practice This Live
The blueprint above is the exact live view that runs during your AI mock interview session. Start a session, receive the same problem Jordan worked through, and get feedback scored against all four rubric dimensions as you go.
Start the AI mock interview for data structures and complexity and run the trending-search question end to end.
Before going live, drilling individual questions in the Software Engineer data structures and complexity question bank builds the vocabulary you need to frame approaches confidently under pressure. For a structured preparation plan before your interview, the Software Engineer preparation guides cover company-specific formats and additional practice paths.
FAQ
Q. What is tested in a software engineer data structures and complexity interview?
A mid-level interview on this topic covers four weighted dimensions: Interviewer Objectives Alignment (30 pts), whether you address the core problem and satisfy the interviewer's goals; Level-Specific Expectations (30 pts), whether your reasoning matches the seniority bar; Technical Proficiency (20 pts), correct implementation and complexity analysis; and Communication and Problem Solving (20 pts), structure, clarifying questions, and handling ambiguity. Knowing the algorithm is necessary but worth only 20% of the total score.
Q. How is a software engineer data structures interview scored?
The rubric allocates 100 points across four dimensions: Interviewer Objectives Alignment (30 pts), Level-Specific Expectations (30 pts), Technical Proficiency (20 pts), and Communication and Problem Solving (20 pts). A candidate who solves the problem correctly but skips framing and trade-off discussion can score well below 70 on the first two dimensions alone, regardless of how clean the implementation is.
Q. What data structure should I use for a top-K problem in a coding interview?
The right answer depends on the workload. A hash map paired with a min-heap of size k gives O(log k) per record update and O(k log k) for getTopK, good when reads and writes are balanced. When writes far outnumber reads, a hash map alone with on-demand sorting can outperform because you avoid heap maintenance on every update. A bucket-based approach indexes by frequency for O(1) amortized operations but uses O(n) auxiliary space. Stating which you choose and why is more valuable than defaulting to heap.
Q. Should I start coding immediately or clarify requirements first in a data structures interview?
Clarify first. The interviewer scores problem framing as part of both Communication and Problem Solving and Level-Specific Expectations. At mid-level, you are expected to ask or state assumptions about tie-breaking, valid k range, and the expected ratio of updates to reads before writing a single line. Jumping straight to code signals you solved the problem you assumed, not the one that was asked.
Q. What are the most common mistakes mid-level engineers make in data structures interviews?
Three mistakes appear most often: coding before framing (skipping approach selection costs the 30-point Interviewer Objectives Alignment dimension), giving imprecise complexity analysis (saying 'O(n log n)' without specifying average vs. worst-case or total auxiliary space), and incomplete edge-case coverage (missing k equal to 0, k larger than distinct items, or leaving tie-breaking undefined).
Q. What is the level-specific bar for a mid-level software engineer data structures interview?
At the mid-level (2 to 5 years), you are expected to arrive at a workable design with at least one solid implementation path without heavy guidance, compare a straightforward solution against an optimized one, write mostly correct code with manageable edge-case handling, and recognize concurrency concerns conceptually. You are not expected to invent specialized streaming algorithms or design lock-free distributed systems.
Q. How long is a data structures interview at a leading tech company?
A typical mid-level software engineer interview on data structures and complexity runs 30 minutes. The time breaks into three phases: 0 to 7 minutes for problem framing and approach selection, 7 to 22 minutes for implementing the core data structure, and 22 to 30 minutes for complexity analysis, edge cases, and trade-off discussion.
One Rung at a Time
The data structures interview is a performance skill. You can know the algorithm, know the blueprint, and still lose points by reaching for the keyboard before framing the problem. The distance between reading this walkthrough and reliably hitting the Phase 1 checklist under live follow-up pressure closes with one action: run the interview for real.
Topics
Ready to practice?
Put what you've learned into practice with AI mock interviews and structured preparation guides.