The Applied Scientist Data Pipelines and Feature Platforms Interview Rewards the Join, Not the Diagram
A mid-level Applied Scientist walks into a 30-minute interview on data pipelines and feature platforms, and the instinct is to treat it like a whiteboard architecture exercise: draw ingestion, draw storage, draw a batch job and a streaming job, done. That instinct isn't wrong, it's just incomplete. The design decision graded most heavily in this interview isn't which boxes you draw. It's whether the join that builds your training data actually reflects what the model would have seen at the moment it made a prediction.
This walkthrough is built on one real interview blueprint, the same rubric and phase structure used to score InterviewStack.io's AI mock interview for Applied Scientist on this exact topic. The scenario: a recommendation team needs a ranking model served from features computed in both batch and near-real-time, at billions of events per day, trusted by more than one scientist. The rubric splits 100 points across four dimensions, and two of them decide most of the outcome before a single line of architecture gets drawn.
Key Findings
- Interviewer Objectives Alignment and Level-Specific Expectations each carry 30 of the interview's 100 rubric points, together outweighing Technical Proficiency and Communication and Problem Solving combined.
- The core design phase runs from minute 6 to minute 19, 13 of the 30 minutes, and is graded against 6 separate expectedChecklist items.
- The reliability phase (minutes 19 to 27) packs 5 checklist items into 8 minutes, including a named requirement to explain point-in-time correctness for training data.
- The interviewer's own objectives explicitly name point-in-time correctness and training-serving consistency as two of the things being probed, not left implicit.
- The sample event in the prompt carries both an event_time and a separate ingest_time field, a built-in test of whether you notice the two aren't the same moment.
- Wrap-up is only 3 minutes (minutes 27 to 30) but still holds 3 scored checklist items on prioritization and what you would validate before rollout.
- Across all four phases, candidates are graded against 18 distinct expectedChecklist items inside a single 30-minute session.
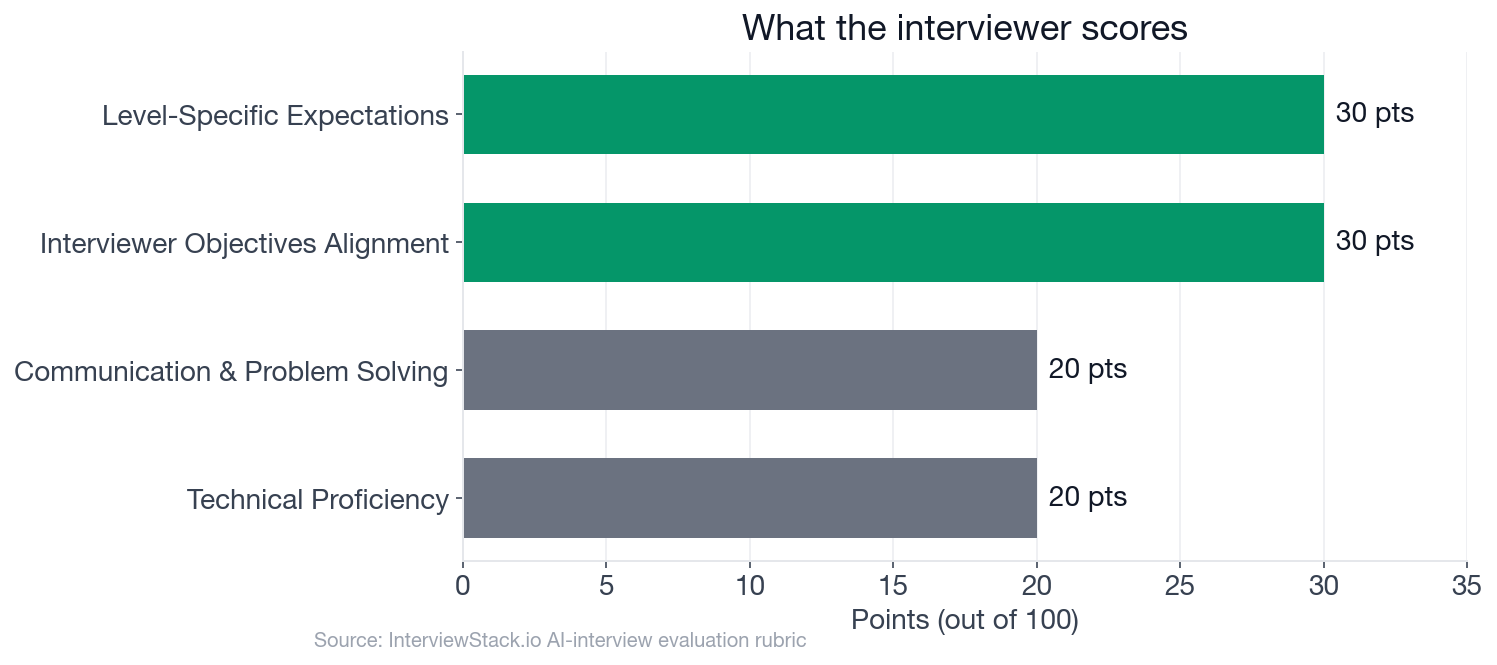
Two of the four dimensions carry 60 of 100 points, and both are judged on reasoning, not on which tools you name.
What This Applied Scientist Interview Actually Puts You Through
Here is the scenario as the interviewer presents it.
The interview question
You are supporting a recommendation team for a large consumer app that wants to launch a new ranking model built on user and item features derived from interaction events such as impressions, clicks, saves, and purchases. The system needs to support offline training datasets for daily model retraining alongside online feature retrieval for real-time inference, at event volume on the order of billions of events per day across regions, with a mix of batch-computed and near-real-time features, and feature definitions that multiple scientists can trust and reuse across model iterations. Here is an example event from the stream:
{
"event_id": "e9f1",
"event_type": "click",
"event_time": "2026-06-10T12:03:11Z",
"ingest_time": "2026-06-10T12:03:18Z",
"user_id": "u123",
"item_id": "i456",
"session_id": "s88",
"device_type": "ios",
"country": "US",
"position": 4
}
Design a data pipeline and feature platform approach for this ranking use case, and walk through how you would ensure the features are reliable and consistent for both training and online serving.
What the interviewer is actually probing: whether you can translate this ambiguous ML use case into concrete choices across ingestion, storage, and serving, whether you reason clearly about batch versus streaming trade-offs, and whether you show practical judgment on point-in-time correctness and offline/online consistency, without needing to invent a company-wide platform strategy.
Where Does a Mid-Level Applied Scientist Actually Lose Points?
The candidate in this walkthrough, Devon, gives answers that sound competent on first read. Each one has a specific, scored gap. Here are four of the six follow-ups the interviewer can ask, picked to cover both the core design phase and the reliability phase where most of the checklist lives.
Turn 1: Streaming Everything, No Trade-off
Interviewer: "How would you decide which features should be computed in batch versus streaming, and what trade-offs would drive that split?"
Turn 2: The Join That Leaks the Future
Interviewer: "If events can arrive late or out of order, how would your design preserve point-in-time correctness for training data?"
Turn 3: Vague Monitoring, No Signals
Interviewer: "What data quality checks and operational metrics would you put in place before scientists trust these features in production?"
Turn 4: Scaling the Whole Store
Interviewer: "If the online feature service starts seeing hot keys for a small set of very active users or items, how would you mitigate latency or reliability issues?"
Why Watching This Isn't the Same as Doing It
Every mistake above reads as obvious once it's on the page, with the rubric line right next to it. That's the trap. Live, the interviewer doesn't hand you the checklist. The follow-ups arrive in an order you don't control, at a pace that doesn't pause for reflection, and a weak answer on Turn 1 boxes you in by Turn 3. A blog post can't reproduce a 30-minute clock and an unscripted follow-up you didn't prepare for.
The only preparation that closes that gap is a live rep under real pressure. That's what the AI mock interview is built to give you.
This Is the Blueprint the AI Interviewer Tracks in Real Time
This is the blueprint a strong candidate hits across all four phases. It's also exactly what the AI mock interview tracks you against in real time, with per-phase, per-dimension feedback once the session ends.
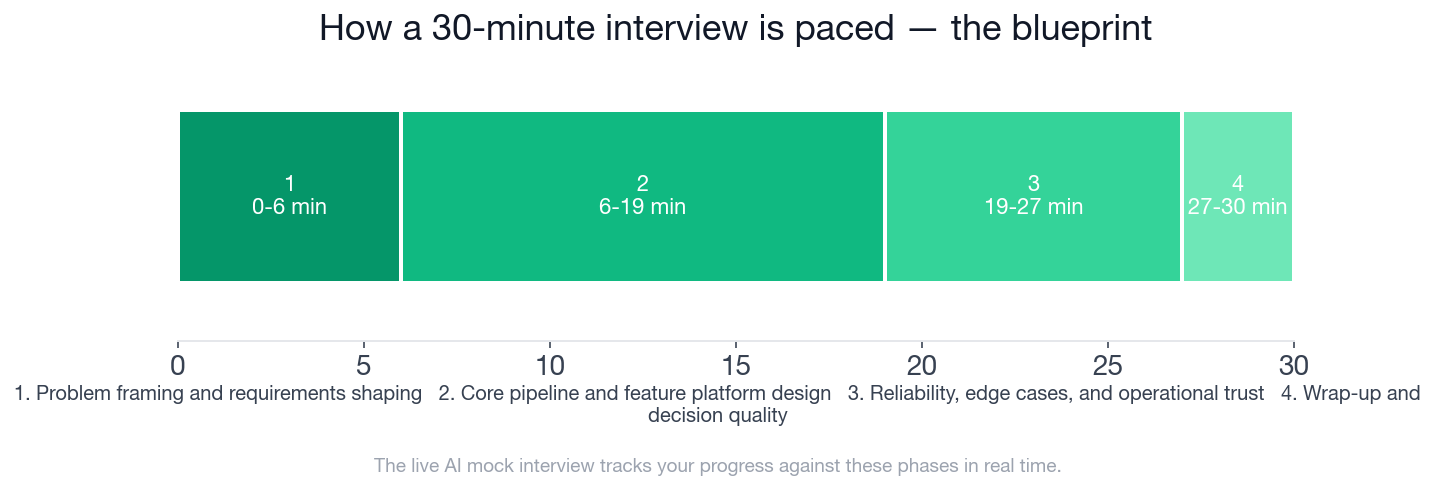
Thirteen of the 30 minutes go to core pipeline and feature platform design alone, but the reliability phase that follows is where point-in-time correctness gets tested directly.
- ✓Clarifies or states assumptions about training cadence, online latency sensitivity, and freshness targets
- ✓Separates offline training use cases from online inference needs
- ✓Identifies key entities such as user, item, event stream, and feature definitions
- ✓Mentions trust requirements like correctness, reproducibility, or consistency early in the discussion
- ✓Proposes ingestion from event producers into durable storage and processing systems
- ✓Describes at least one path for batch feature computation and one for near-real-time feature computation
- ✓Explains how features are registered or defined so scientists can reuse them
- ✓Provides a plausible offline store and online store separation or equivalent design
- ✓Explains how training datasets are built using historical feature values at event time rather than current values
- ✓Addresses deduplication or idempotent processing using event identifiers, checkpoints, or equivalent mechanisms
- ✓Discusses late or out-of-order data and names a concrete handling approach such as watermarking, event-time windows, or bounded lateness policies
- ✓Mentions schema evolution handling and validation to catch breaking changes
- ✓Defines a few concrete monitoring signals such as freshness lag, null rates, distribution drift, join rates, or online latency
- ✓Explains how to backfill or recompute features after a logic bug while preserving versioning or reproducibility
- ✓Identifies at least one online serving risk such as stale values, cache pressure, or hot keys and proposes a mitigation
- ✓Summarizes major design choices and why they fit the stated use case
- ✓Calls out one or two scoped simplifications they would make for a first version
- ✓Shows awareness of what they would validate experimentally before broader rollout
Practice This Before You Walk Into the Real One
Reading four turns and nodding along isn't the same as producing them live, in whatever order the interviewer picks, with a 30-minute clock running and no time to second-guess your join logic. The AI mock interview for Applied Scientist: Data Pipelines and Feature Platforms runs this exact scenario, asks unscripted follow-ups, and scores you against all four rubric dimensions when you're done, so you know which phase actually cost you points instead of guessing. If you want to drill the underlying concepts first, the Data Pipelines and Feature Platforms question bank breaks the topic into batch versus streaming design, point-in-time correctness, schema evolution, and online serving reliability, one question at a time. For a broader view of what the role expects in 2026, see what companies actually want from Applied Scientists.
FAQ
Q. What is this Applied Scientist data pipelines and feature platforms interview actually testing?
It tests whether you can turn an ambiguous ranking-model use case into a concrete architecture across ingestion, batch and streaming feature computation, offline and online storage, and serving, while reasoning correctly about point-in-time correctness and training-serving consistency. Two of the four rubric dimensions, Interviewer Objectives Alignment and Level-Specific Expectations, each worth 30 of 100 points, are graded on that reasoning rather than on naming the right tools.
Q. How much of the score depends on system design compared to communication?
Technical Proficiency and Communication and Problem Solving are each worth 20 of 100 points, 40 points combined. The other 60 points, split evenly between Interviewer Objectives Alignment and Level-Specific Expectations, reward whether you addressed what the interviewer actually asked and whether your depth matches a mid-level Applied Scientist, regardless of how polished your explanation sounds.
Q. What is point-in-time correctness and why does this interview test it so directly?
Point-in-time correctness means a training example is built from the feature values that existed at the moment the labeled event happened, not the values that exist now. The interview tests it directly because joining current feature state to historical labels leaks future information into training data, a mistake the expectedChecklist explicitly calls out under the core pipeline design phase.
Q. How long is the interview and how is the time split across phases?
The interview runs 30 minutes across four phases: problem framing and requirements shaping (0 to 6 minutes, 4 checklist items), core pipeline and feature platform design (6 to 19 minutes, 6 checklist items), reliability, edge cases, and operational trust (19 to 27 minutes, 5 checklist items), and wrap-up and decision quality (27 to 30 minutes, 3 checklist items).
Q. What is the most common mistake mid-level Applied Scientist candidates make in this interview?
The most common mistake is treating feature freshness as strictly better and joining training labels to the current feature state instead of the feature values that existed at the label's event time. It reads as a reasonable design choice but leaks future information into the model and directly misses one of the core pipeline design phase's expectedChecklist items.
Q. Is this a coding interview or a system design interview?
It is a system design interview focused on applied ML data infrastructure, not an algorithmic coding round. The forbidden-skills list for this blueprint explicitly excludes deep neural network architecture, LLM fine-tuning or prompt engineering, and pure algorithmic coding challenges, keeping the focus on pipeline and feature platform design judgment.
Q. How can I practice this exact interview before the real one?
The AI mock interview for Applied Scientist on Data Pipelines and Feature Platforms runs this scenario live, asks unscripted follow-ups in real time, and scores you against all four rubric dimensions afterward, so you find out which phase you are actually losing points in instead of guessing.
The Join Is the Interview
Everything else in this interview, the ingestion diagram, the storage choices, the tool names, is scaffolding around one decision: does your training data reflect what the model would actually have seen at inference time. Candidates who treat that as an afterthought lose the two dimensions worth 60 points before the interviewer ever asks about hot keys. Candidates who lead with it are already answering the question the rubric is actually asking.
Topics
Ready to practice?
Put what you've learned into practice with AI mock interviews and structured preparation guides.